官方平台用户指南¶
本页是官方企业微信文档的仓库内整理版,方便查训练、模型发布、评测入口和平台变量。官方页面需要登录态,所以这里保留可长期查阅的文字和图片。
同步来源:
| 项目 | 内容 |
|---|---|
| 原文标题 | Tencent Angel Machine Learning Platform User Guide |
| 原始链接 | https://doc.weixin.qq.com/doc/w3_ALQATQZyACgCNqA7rGAELTHOn2rc5?scode=AJEAIQdfAAo65iNyGaALQATQZyACg |
| 本页同步时间 | 2026-04-25 |
| 官方最近保存时间 | 2026-04-23 19:01 |
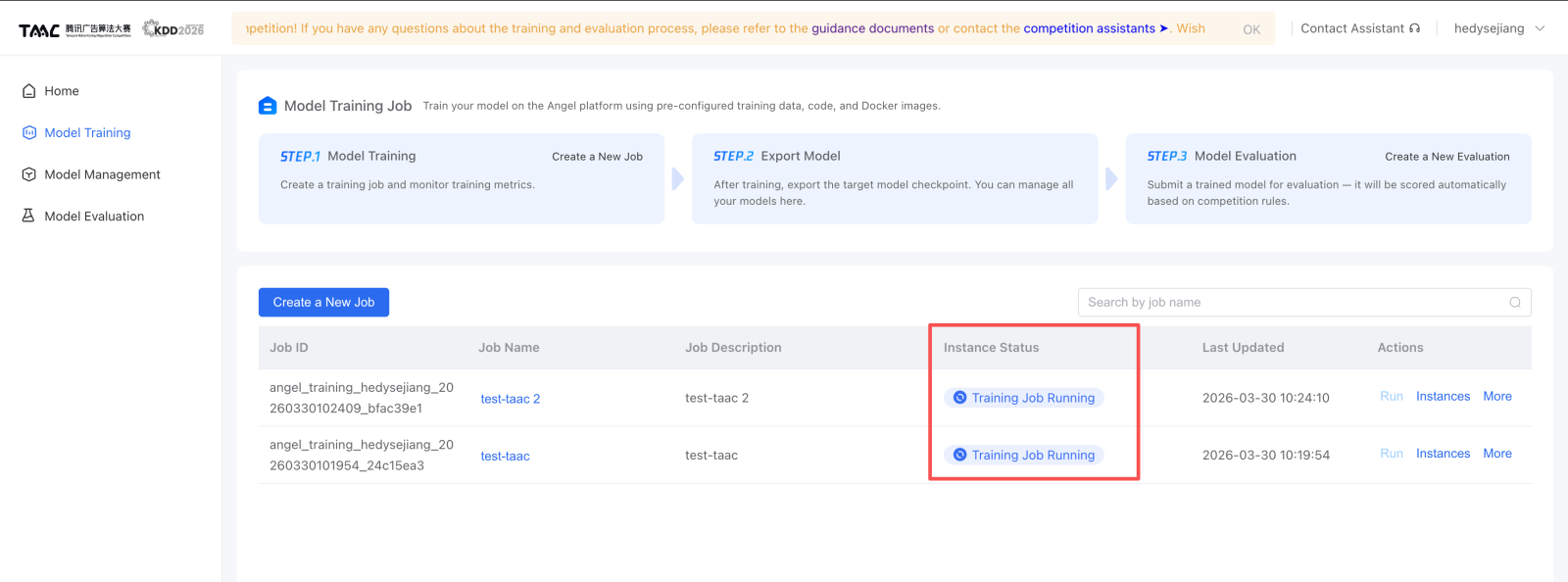
训练任务怎么走¶
官方平台的训练流程是:
- 创建训练任务,填写 Job Name 和 Job Description。
- 上传本地脚本,或在平台里新建脚本。
- 提交任务。
- 点击 Run 启动。
- 进入 Instances 查看 Output 和 Logs。
- 需要提前停止时点击 Stop。
本仓库上传训练任务时,通常上传 线上 Bundle 上传 里生成的 run.sh 和 code_package.zip。
官方图示:
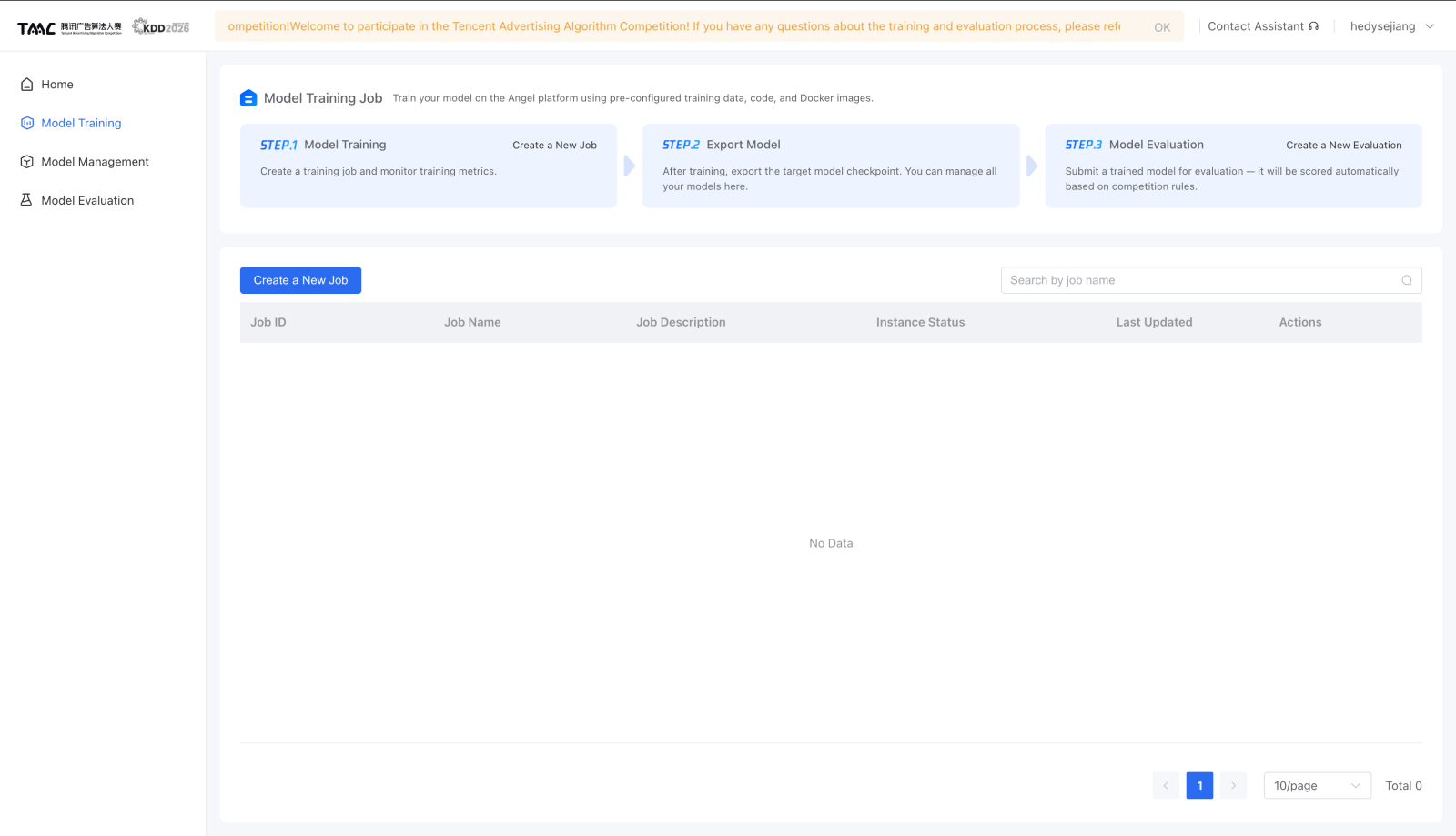
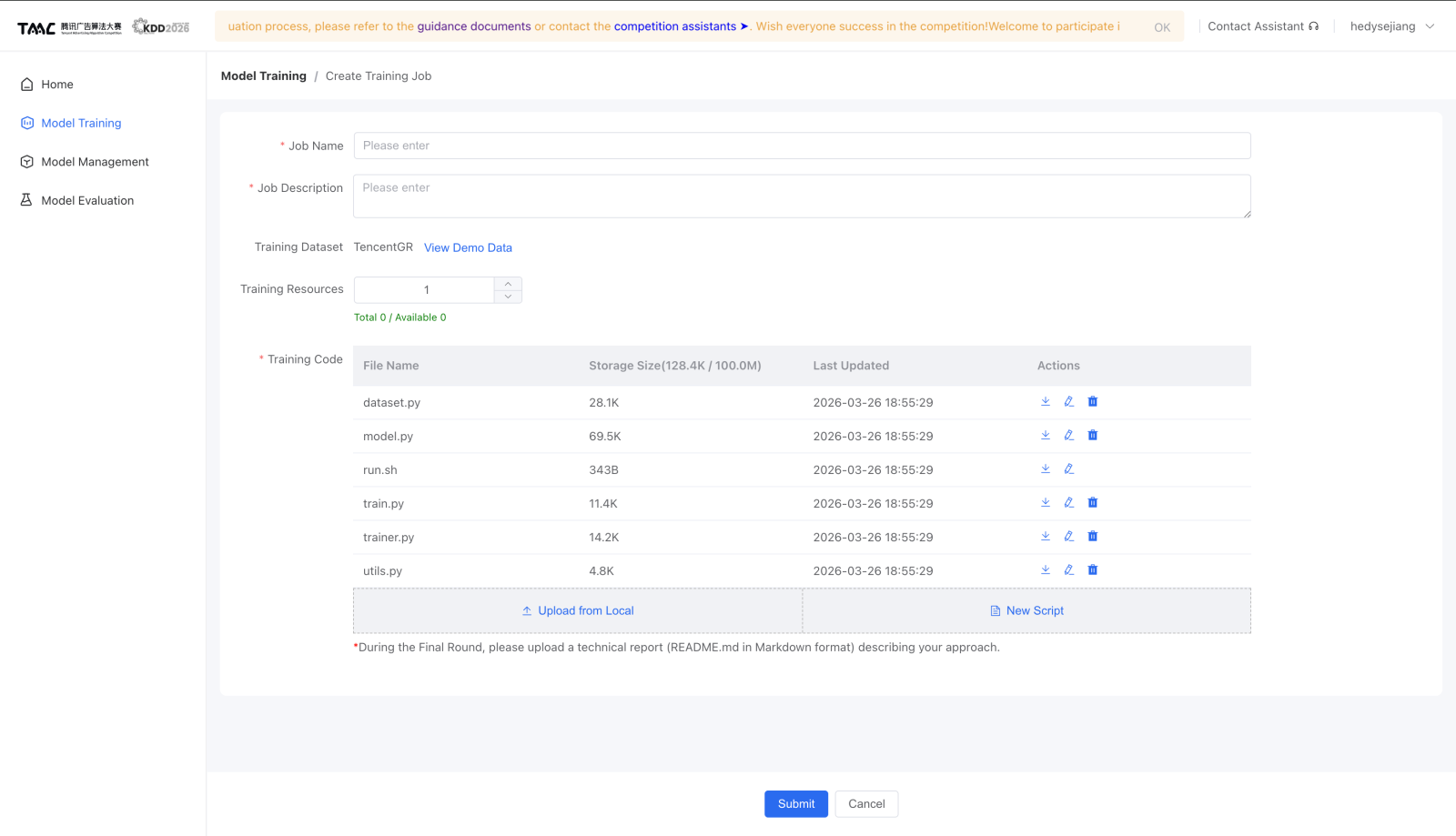
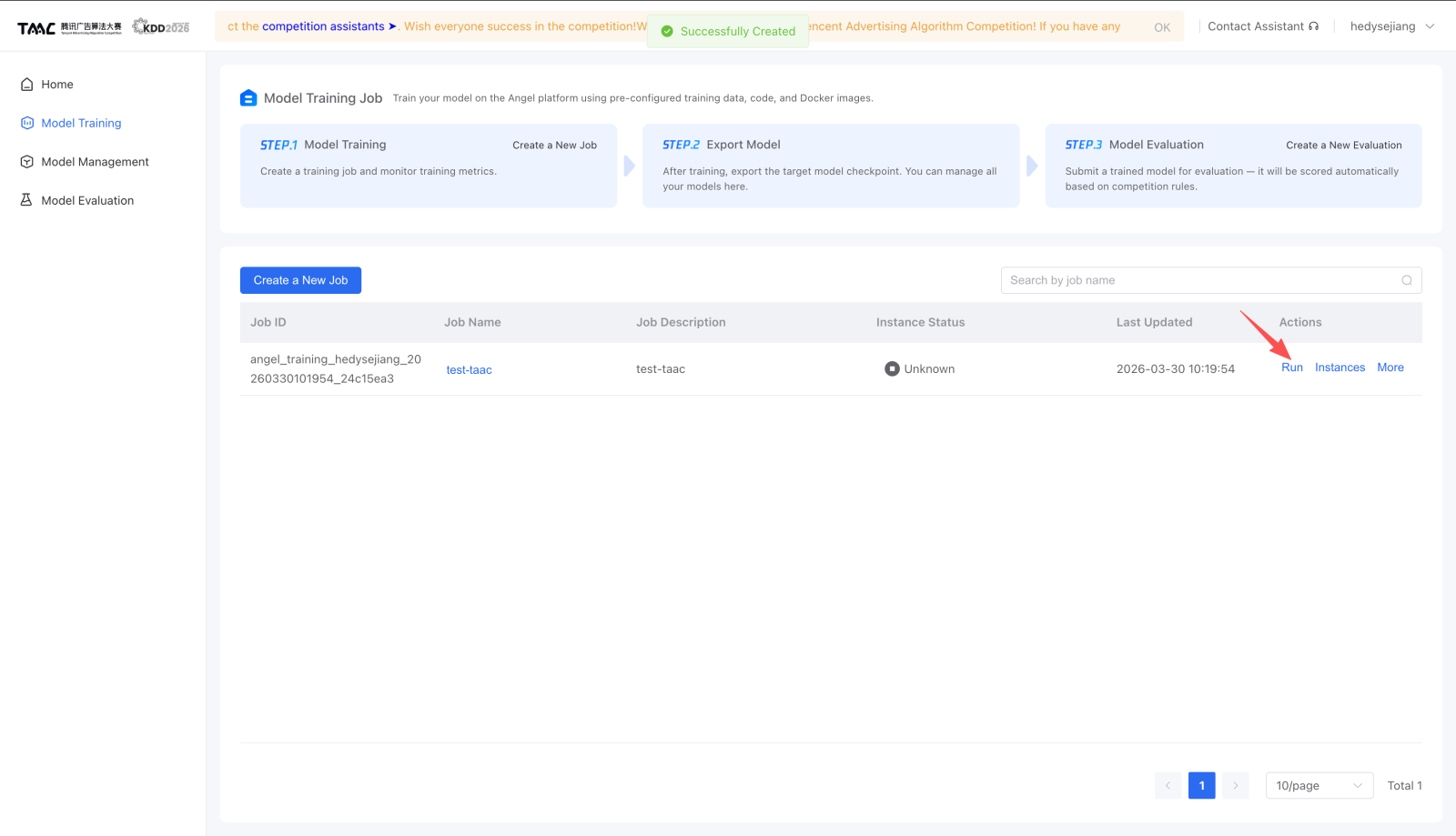
模型怎么发布¶
训练完成后,模型发布入口在训练任务的实例产物页:
- 进入训练任务的 Instances。
- 打开 Output。
- 选中要发布的 checkpoint。
- 点击 Publish。
- 填写 Model Name 和 Model Description。
- 提交后 Publish Status 变为 Released。
发布后的模型可以在 Model Management 查看。

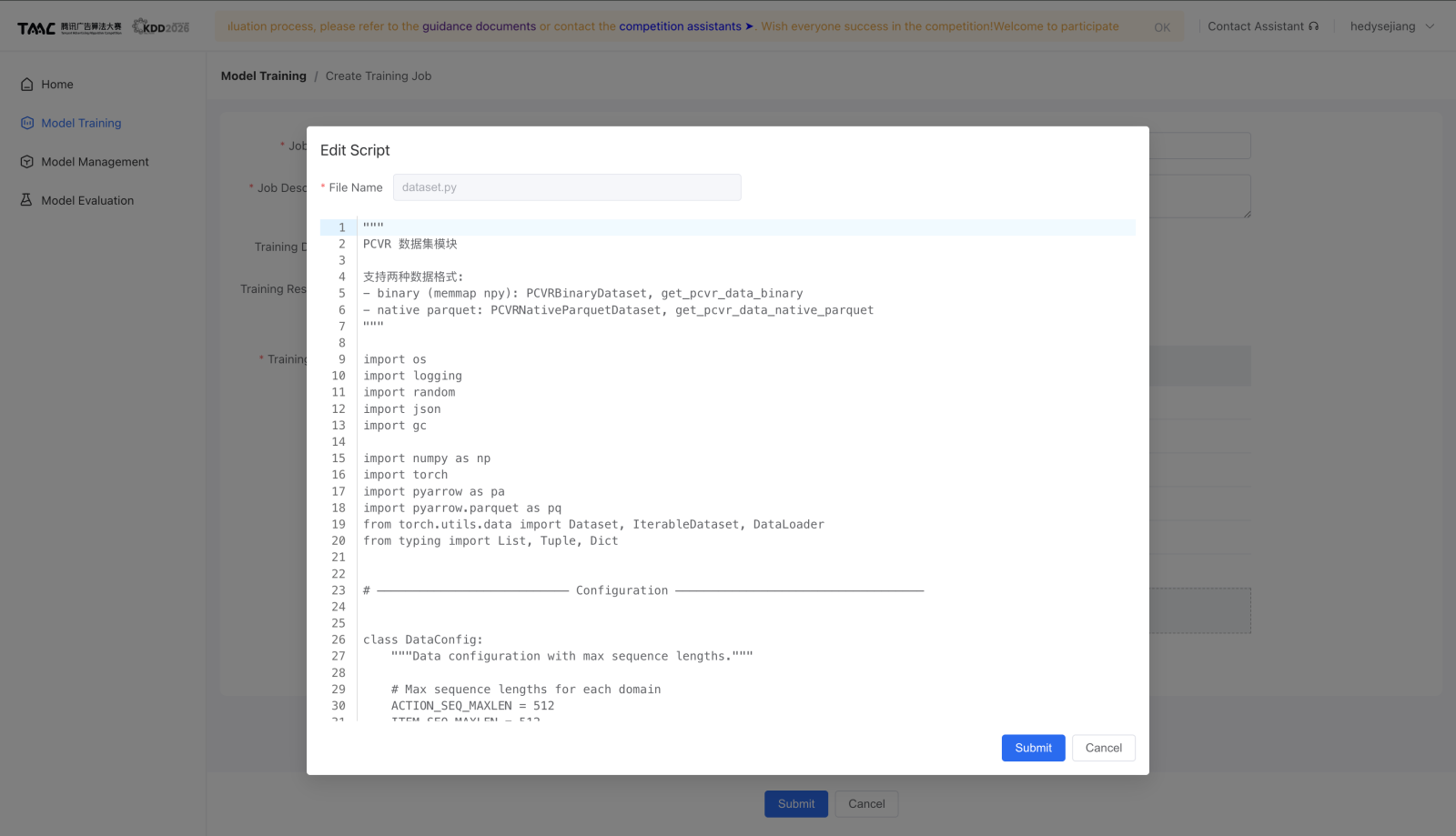
评测任务怎么走¶
评测入口有两种:
- 在 Model Management 里找到模型,点击 Model Evaluation。
- 进入 Model Evaluation 页面,点击 Create Evaluation。
官方要求:
| 项目 | 要求 |
|---|---|
| 主入口文件 | 必须叫 infer.py |
| 入口函数 | infer.py 中必须有无参数 main() |
| 输出文件 | 必须在 EVAL_RESULT_PATH 下写 predictions.json |
| 上传大小 | 脚本总大小不超过 100 MB |
| 附加脚本 | 可上传 dataset.py、model.py 等辅助文件 |
本仓库的推理 bundle 会生成符合入口要求的 infer.py。
平台规格¶
官方文档给出的单个 GPU 切片规格:
| 资源 | 规格 |
|---|---|
| 计算份额 | 单卡 20% |
| GPU 显存 | 19 GiB |
| CPU 核数 | 9 |
| 内存 | 55 GiB |
官方软件环境摘要:
| 软件 | 版本 |
|---|---|
| Ubuntu | 22.04 |
| CUDA | 12.6 |
| cuDNN | 9.5.1 |
| NCCL | 2.26.2+cuda12.6 |
| Python | 3.10.20 |
对本仓库最相关的预装包包括 torch==2.7.1+cu126、torchrec==1.2.0+cu126、fbgemm_gpu==1.2.0+cu126、pyarrow==23.0.1 和 pandas==2.3.3。
真实任务日志中的网络、代理和依赖源情况见 线上运行环境速查。
训练环境变量¶
| 变量 | 作用 |
|---|---|
USER_CACHE_PATH |
用户缓存目录,训练和评测共用 |
TRAIN_DATA_PATH |
训练数据目录 |
TRAIN_CKPT_PATH |
checkpoint 保存目录 |
TRAIN_TF_EVENTS_PATH |
TensorBoard event 文件目录 |
官方要求 checkpoint 目录名前缀为 global_step,目录名长度不超过 300 个字符,只使用字母、数字、下划线、连字符、等号和点号。
本仓库训练产物会写出 global_step*/model.safetensors,并在同目录保存 schema.json 与 train_config.json。
评测环境变量¶
| 变量 | 作用 |
|---|---|
USER_CACHE_PATH |
用户缓存目录 |
MODEL_OUTPUT_PATH |
已发布模型产物目录 |
EVAL_DATA_PATH |
测试数据目录 |
EVAL_RESULT_PATH |
predictions.json 输出目录 |
EVAL_INFER_PATH |
用户上传推理脚本所在目录 |
predictions.json 格式:
key 必须是测试集里的有效 user id,value 是 0 到 1 的预测概率。
依赖准备脚本¶
官方评测任务允许额外上传一个严格命名为 prepare.sh 的脚本。它会在推理前、平台预激活 Conda 环境中执行。
只有在平台默认环境确实缺少依赖时才使用它。核心 CUDA / PyTorch 栈不建议在这里覆盖安装。
图集¶
这些图片来自官方文档内嵌资源,已经落到仓库本地:

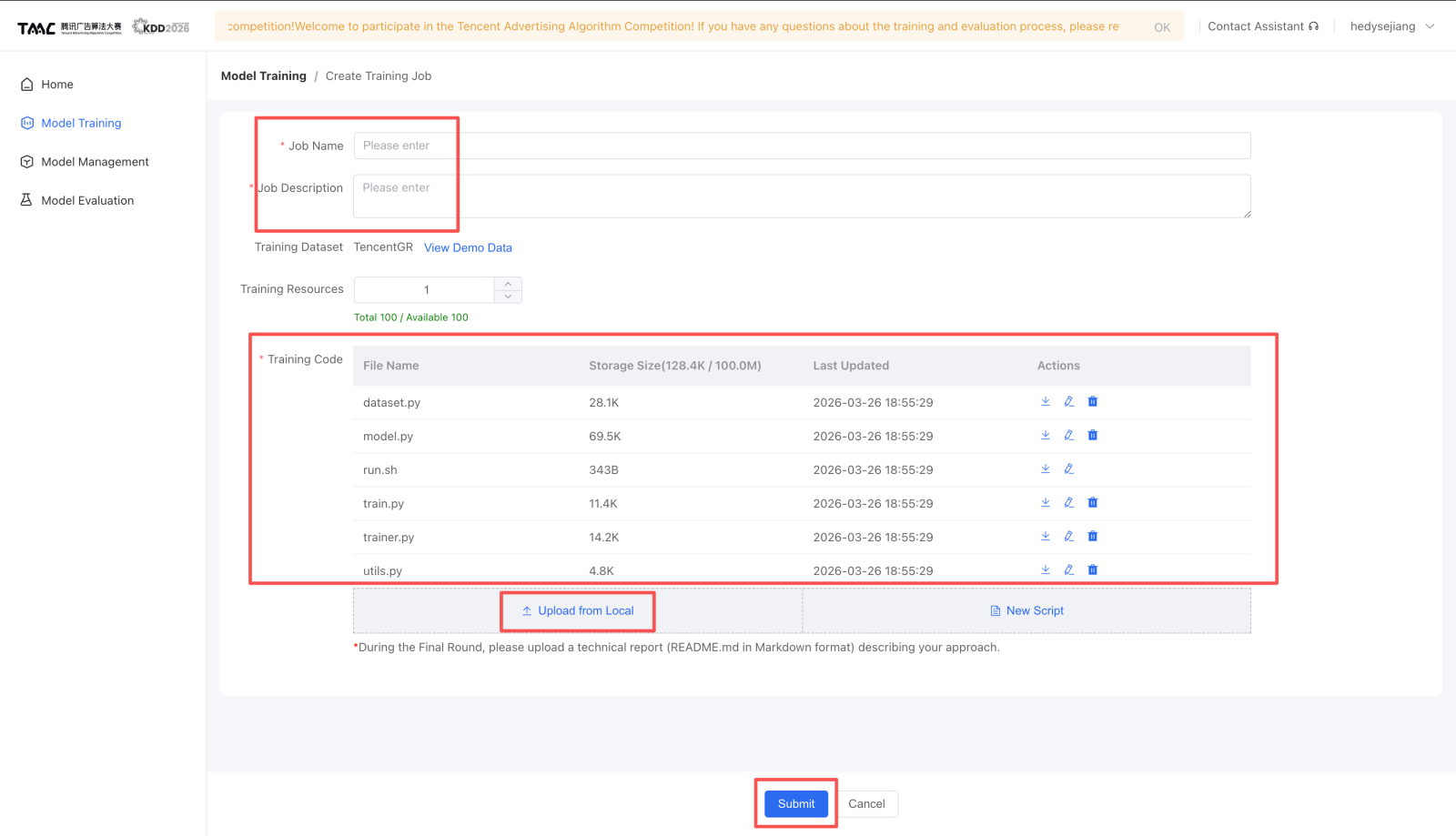


维护这页¶
更新官方文档快照时,正文和图片都应落到仓库内。图片放在:
改完后运行: