OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender¶
Converted from the LaTeX source under arXiv-2510.26104v3.
Converted figures live under img/onetrans/ and are referenced directly from this markdown file.
Accepted at The Web Conference 2026 (WWW 2026). Camera-ready version forthcoming.
Authors¶
Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun.
Notes:
- Zhaoqi Zhang, Haolei Pei, and Jun Guo contributed equally.
- Shaowei Liu and Aixin Sun are corresponding authors.
Affiliations:
- Nanyang Technological University, Singapore
- ByteDance, Singapore
- ByteDance, Hangzhou, China
Abstract¶
In industrial recommendation systems, recent progress in scaling often happens along two separate directions: feature interaction modules such as Wukong and RankMixer, and user-behavior sequence modules such as LONGER. Although effective, these lines of work usually remain architecturally separated, which limits bidirectional information exchange and makes unified optimization difficult. OneTrans addresses this gap with a single Transformer backbone that jointly performs user-behavior sequence modeling and feature interaction. A unified tokenizer converts both sequential and non-sequential attributes into one token sequence. Stacked OneTrans blocks then process this unified sequence using mixed parameterization: similar sequential tokens share parameters, while non-sequential tokens use token-specific parameters. Combined with causal attention and cross-request KV caching, OneTrans can precompute and reuse intermediate representations to reduce both training and inference cost. On industrial-scale datasets, the model scales effectively with model size, consistently outperforms strong baselines, and reports a 5.68% lift in per-user GMV in online A/B testing.
CCS Concepts¶
- Information systems
- Information retrieval
- Recommender systems
Keywords¶
- Recommender System
- Ranking Model
- Scaling Laws
1. Introduction¶
Recommendation systems are a core component of large-scale information services such as e-commerce, streaming media, and social networks [zhou2018deepnetworkclickthroughrate; feng2019deepsessionnetworkclickthrough; pancha2022pinnerformer; chang2023pepnet; xia2023transact; zhang2024wukong; zhai2024actions]. Industrial systems commonly use a cascaded architecture [covington2016deep; liu2017cascade; qin2022rankflow]. A recall stage first narrows a billion-scale corpus down to hundreds of candidates [zhu2018learning; huang2024comprehensive], and a ranking stage then scores those candidates and returns the top results [Wang_2021; gui2023hiformerheterogeneousfeatureinteractions; xia2023transact; zhang2024wukong; zhu2025rankmixerscalingrankingmodels]. Deep Learning Recommendation Models (DLRMs) [naumov2019deep] are now standard in this ranking stage.
This paper focuses on ranking. In mainstream ranking systems, two modules are usually improved separately:
- Sequence modeling, which encodes multi-behavior histories into candidate-aware representations using attention, local sequence modeling, or Transformers [zhou2018deepnetworkclickthroughrate; kang2018selfattentivesequentialrecommendation; sun2019bert4recsequentialrecommendationbidirectional; chai2025longer].
- Feature interaction, which models higher-order crosses among non-sequential features such as user profile, item profile, and context [guo2018deepfmendtoendwide; Wang_2021; gui2023hiformerheterogeneousfeatureinteractions; zhu2025rankmixerscalingrankingmodels].
The dominant architecture is an encode-then-interaction pipeline: user behavior is first compressed into a sequence representation, then concatenated with non-sequential features, and finally sent through a feature-interaction module. This design has two drawbacks. First, sequence modeling and feature interaction are separated, which weakens bidirectional information exchange [zeng2024interformer]. Second, the fragmented architecture cannot benefit as directly from mature large-language-model optimizations such as KV caching, memory-efficient attention, and mixed precision.
Recent work on scaling laws in RecSys follows the same two-track pattern. Wukong [zhang2024wukong] and RankMixer [zhu2025rankmixerscalingrankingmodels] improve feature interaction. LONGER [chai2025longer] improves long-sequence modeling. These methods produce clear gains, but they still scale disconnected components instead of scaling a single unified backbone.
OneTrans is proposed as a unified alternative. It uses a single Transformer-style backbone to jointly process both sequential and non-sequential features. A unified tokenizer maps multi-behavior sequences into sequential tokens and user, item, and context attributes into non-sequential tokens. The resulting mixed token sequence is passed through stacked OneTrans blocks. Unlike LLMs, where tokens are homogeneous text pieces, recommendation tokens come from diverse feature sources. OneTrans therefore adopts mixed parameterization: all sequential tokens share a single set of Q, K, V, and FFN weights, while each non-sequential token receives token-specific parameters, following the heterogeneous-feature insight of HiFormer [gui2023hiformerheterogeneousfeatureinteractions].
This unified formulation offers three practical advantages. First, it allows sequential and non-sequential features to interact throughout the same stack. Second, it makes entire-model scaling more natural by adjusting backbone depth and width instead of scaling separate subsystems. Third, it directly inherits LLM optimization techniques, especially FlashAttention [dao2022flashattention], mixed precision [micikevicius2017mixed], and cross-request KV caching [chai2025longer]. In particular, cross-candidate and cross-request KV caching reduces serving complexity from \(O(C)\) to \(O(1)\) with respect to the number of candidates \(C\) in a request.
The paper summarizes its contributions as follows:
- Unified framework. OneTrans introduces a single Transformer backbone for ranking, with a unified tokenizer that maps sequential and non-sequential features into one token sequence.
- Recommender-specific customization. The model uses mixed parameterization so heterogeneous non-sequential tokens keep token-specific projections while sequential tokens share parameters.
- Efficient training and serving. Pyramid stacking prunes sequential queries layer by layer, and cross-request KV caching reuses user-side computation. The system also uses FlashAttention, mixed precision, and related LLM optimizations.
- Scaling and deployment. OneTrans shows near log-linear performance gains with increased model size and delivers significant online business improvements under production latency constraints.
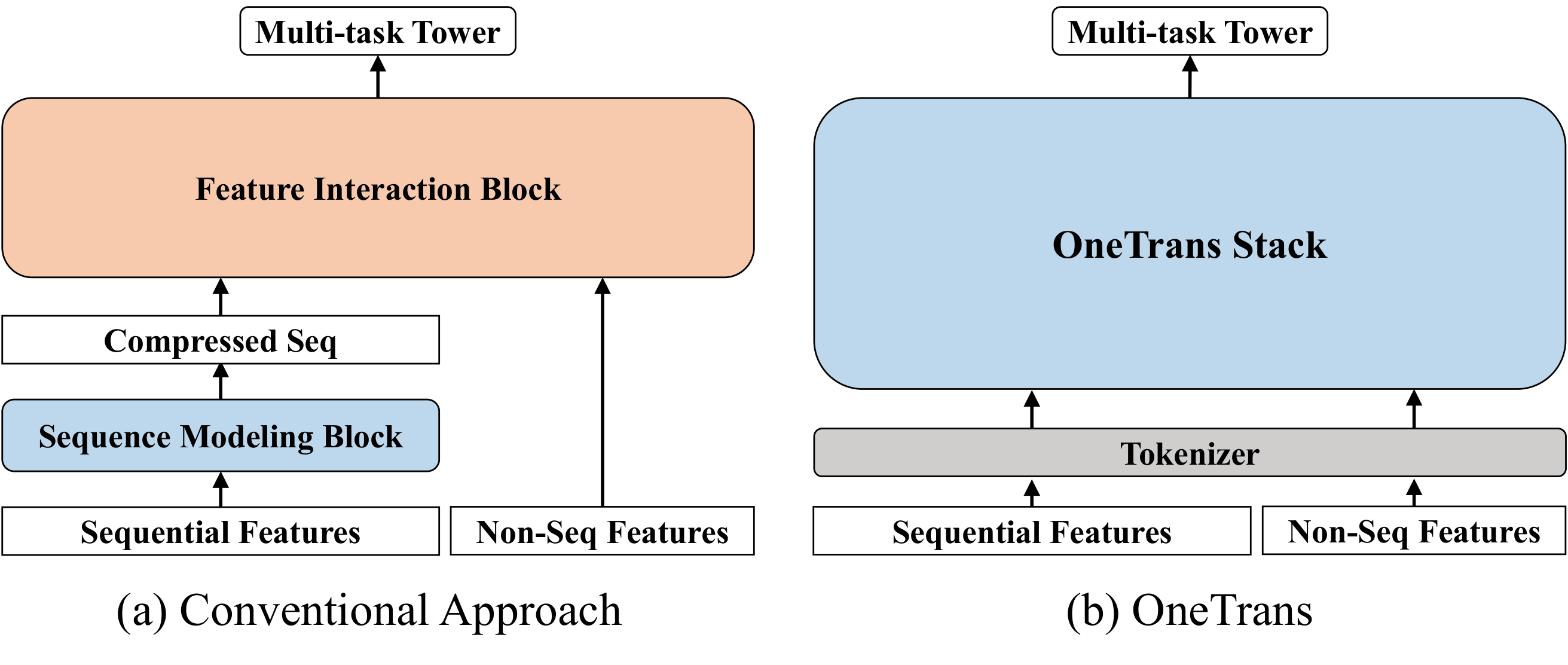
Figure 1. Architectural comparison. In the conventional pipeline, sequence features are encoded first and merged with non-sequential features only before a separate feature-interaction module. OneTrans instead performs joint modeling of sequential and non-sequential features inside one Transformer-style stack.
2. Related Work¶
Early CTR and ranking systems such as DIN [zhou2018deepnetworkclickthroughrate] and DSIN [feng2019deepsessionnetworkclickthrough] use local attention to learn candidate-conditioned summaries of user behavior, but they compress behavior into fixed-length vectors and therefore struggle with long-range dependency modeling [zhou2018deepevolutionnetworkclickthrough]. Self-attentive sequential recommendation models such as SASRec [kang2018selfattentivesequentialrecommendation], BERT4Rec [sun2019bert4recsequentialrecommendationbidirectional], and BST [chen2019behaviorsequencetransformerecommerce] improve this by modeling full-history dependencies. LONGER [chai2025longer] further scales sequence modeling to ultra-long histories in industrial settings. However, these approaches usually remain separate from feature-interaction modules and therefore still perform late fusion rather than full joint optimization [zeng2024interformer].
Feature interaction has its own history. Classical models such as Wide and Deep [cheng2016widedeeplearning], FM and DeepFM [chang2010training; guo2018deepfmendtoendwide], and DCN / DCNv2 [wang2017deepcrossnetwork; Wang_2021] provide efficient low-order or bounded-order interactions, but their gains can saturate as more layers are added [zhang2024wukong]. Attention-based models such as AutoInt [Song_2019] and HiFormer [gui2023hiformerheterogeneousfeatureinteractions] make interaction modeling more flexible, and recent large-scale systems such as Wukong [zhang2024wukong] and RankMixer [zhu2025rankmixerscalingrankingmodels] show clearer scaling behavior. Even so, these systems typically preserve the interaction-stage abstraction, so unified optimization with sequence modeling is still limited.
InterFormer [zeng2024interformer] is one of the first attempts to explicitly bridge sequence modeling and feature interaction by allowing bidirectional exchange between them. But it still keeps them as distinct modules linked by a cross architecture, which adds complexity and fragments execution. Generative recommender systems such as HSTU [zhai2024actions] offer a complementary direction by framing recommendation as sequential transduction, but DLRM-style ranking still needs strong support for rich non-sequential features. OneTrans is positioned as a unified ranking architecture that merges these concerns into a single production-friendly Transformer backbone.
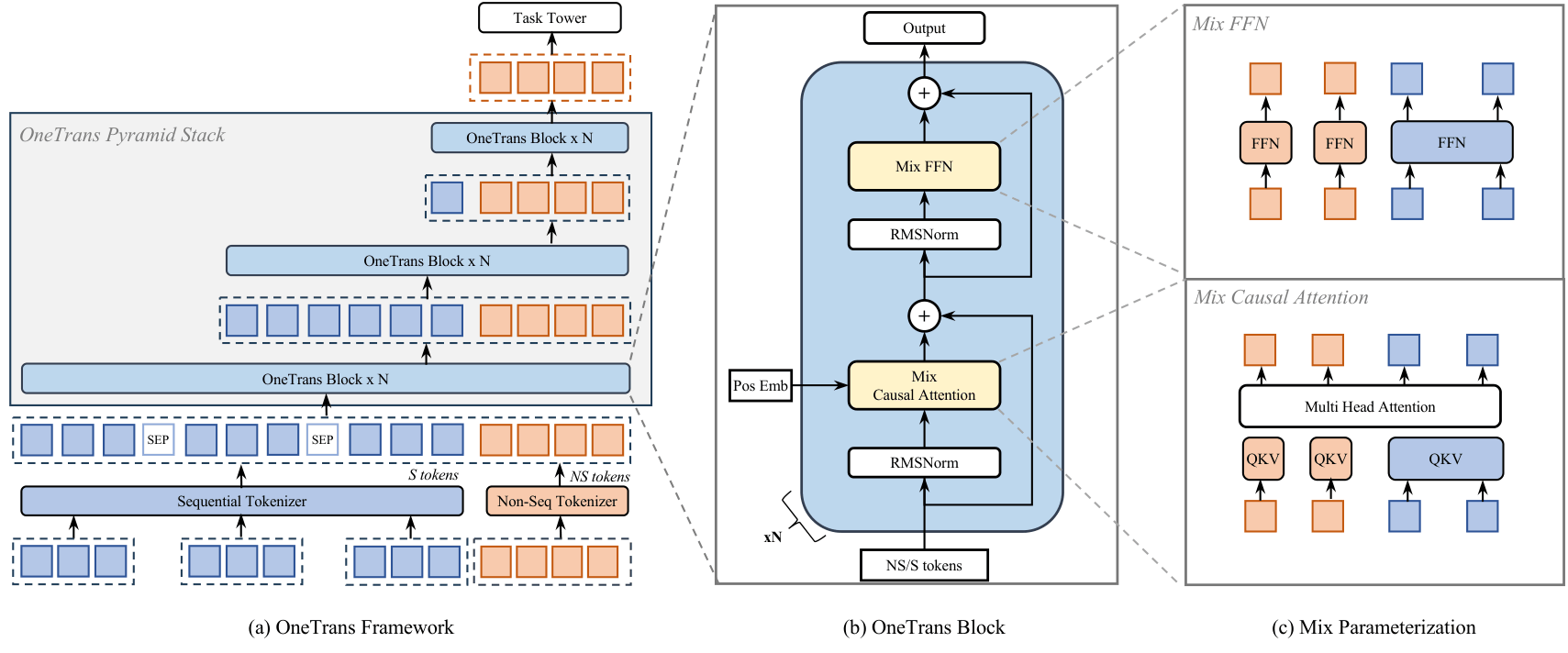
Figure 2. OneTrans system architecture. Sequential and non-sequential features are tokenized separately. After inserting [SEP] between user-behavior sequences, the unified token sequence is fed into stacked OneTrans pyramid blocks that progressively shrink the sequential token length until it matches the number of non-sequential tokens. Each block is a pre-norm causal Transformer with Mixed Causal Attention and Mixed FFN. Mixed means that sequential tokens share one set of QKV and FFN weights, while each non-sequential token gets token-specific parameters.
3. Methodology¶
Before presenting the architecture, the paper defines the industrial ranking task. For each user \(u\), the recall stage returns a candidate set. The ranking model then predicts a score for candidate item \(i\):
where \(\mathcal{NS}\) is the set of non-sequential features, \(\mathcal{S}\) is the set of user behavior sequences, and \(\Theta\) are trainable parameters. Typical predictions include CTR and CVR:
3.1 Framework Overview¶
OneTrans uses a unified tokenizer that maps sequential features into S-tokens and non-sequential features into NS-tokens. The initial token sequence is:
The S-side contains \(L_S\) sequential tokens, the NS-side contains \(L_{NS}\) non-sequential tokens, and every token has dimension \(d\). Learnable [SEP] tokens are inserted between different user-behavior sequences.
The backbone then applies stacked OneTrans blocks. For block \(n\), the update is:
MixedMHA and MixedFFN use shared parameters for sequential tokens and token-specific parameters for non-sequential tokens. A unified causal mask ensures autoregressive attention: sequential tokens can see only earlier sequential positions, while non-sequential tokens can attend over all earlier positions, including the full sequential history. By stacking blocks and applying pyramid truncation to the sequential side, the model progressively distills long histories into compact higher-order information inside the non-sequential tokens.
The paper highlights four kinds of interaction that happen within the same stack:
- Intra-sequence interaction within a behavior sequence.
- Cross-sequence interaction across multiple behavior sequences.
- Multi-source feature interaction across user, item, and context attributes.
- Sequence-feature interaction between behavioral evidence and static/contextual signals.
3.2 Features and Tokenization¶
To construct \(\mathbf{X}^{(0)}\), OneTrans first embeds all raw inputs and then separates them into sequential and non-sequential subsets. Each subset is tokenized independently.
3.2.1 Non-Sequential Tokenization¶
Non-sequential features include numerical signals such as price or historical CTR, and categorical signals such as user ID or item category. After bucketization or one-hot encoding, they are embedded and turned into \(L_{NS}\) non-sequential tokens using one of two strategies.
Group-wise tokenizer, aligned with RankMixer [zhu2025rankmixerscalingrankingmodels]:
where features are manually partitioned into semantic groups \(\{\mathbf{g}_1, \dots, \mathbf{g}_{L_{NS}}\}\).
Auto-Split tokenizer:
Auto-Split uses a single dense projection and then splits the output into multiple tokens. It reduces kernel-launch overhead and, according to the paper's experiments, performs better than manual grouping.
3.2.2 Sequential Tokenization¶
OneTrans accepts a multi-behavior sequence set:
Each event embedding \(\mathbf{e}_{ij}\) is built from an item ID together with side information such as category or price. Because different behavior streams may have different raw dimensions, each sequence is projected into the common hidden dimension \(d\) with a shared sequence-specific projection:
The aligned sequences are then merged into one token stream using one of two rules:
- Timestamp-aware fusion: interleave events by time, with sequence-type indicators.
- Timestamp-agnostic fusion: concatenate sequences by behavior impact, for example purchase before add-to-cart before click, and insert learnable [SEP] tokens between sequences.
The merged sequential token sequence is:
The ablations later show that timestamp-aware fusion performs better when timestamps are available, and that [SEP] tokens are useful when using timestamp-agnostic fusion.
3.3 OneTrans Block¶
Each OneTrans block is a pre-norm causal Transformer operating on \(L_S\) sequential tokens followed by \(L_{NS}\) non-sequential tokens. Since recommendation tokens differ strongly in semantics and statistics, the model applies RMSNorm [zhang2019root] as pre-norm to all token types to stabilize optimization.
3.3.1 Mixed Causal Attention¶
Let \(\mathbf{x}_i \in \mathbb{R}^{d}\) be token \(i\). The corresponding Q, K, and V vectors are:
The projection matrix depends on the token type:
for \(\Psi \in \{Q, K, V\}\).
This design creates three effects:
- S-side: each sequential token attends only to earlier sequential positions.
- NS-side: each non-sequential token attends over the entire sequential history plus preceding non-sequential tokens.
- Pyramid support: because causal masking concentrates information toward later positions, later sequential tokens become natural candidates for retention in the pyramid schedule.
3.3.2 Mixed FFN¶
The feed-forward network uses the same parameterization pattern:
where FFN parameters are shared for sequential tokens and token-specific for non-sequential tokens.
Relative to a standard causal Transformer, the main architectural change is therefore not the attention mechanism itself, but how parameters are assigned across heterogeneous token types.
3.4 Pyramid Stack¶
Because causal masking concentrates information toward later positions, OneTrans uses a pyramid schedule. At each layer, only a tail subset of the most recent sequential tokens emits queries, while keys and values are still computed over the full current sequence.
Let the input token list be \(\mathbf{X} = \{\mathbf{x}_i\}_{i=1}^{L}\) and let the retained query index set be:
Queries are computed only for \(i \in \mathcal{Q}\):
while keys and values are still computed for all positions. After attention, only outputs for \(i \in \mathcal{Q}\) are retained, reducing the token length from \(L\) to \(L'\) and creating a pyramidal hierarchy.
The paper emphasizes two benefits:
- Progressive distillation: long user histories are compressed into a smaller set of informative tail queries.
- Compute efficiency: attention cost becomes \(O(LL'd)\) and FFN cost scales linearly with \(L'\), which significantly reduces FLOPs and activation memory.
3.5 Training and Deployment Optimization¶
3.5.1 Cross-Request KV Caching¶
In industrial systems, samples from the same request are often processed contiguously. Their sequential tokens are identical across candidates, while non-sequential candidate features vary. OneTrans exploits this by splitting computation into two stages.
- Stage I, S-side, once per request: process all sequential tokens with causal masking and cache their keys, values, and attention outputs.
- Stage II, NS-side, per candidate: compute non-sequential tokens for each candidate and perform cross-attention against the cached sequential-side keys and values, followed by token-specific FFNs.
Candidate-specific sequences that cannot reuse the shared cache are pre-aggregated into non-sequential tokens. Since user behavior is append-only, the cache is also reused across requests: a new request only computes incremental keys and values for newly added behaviors. This reduces per-request sequence computation from \(O(L)\) to \(O(\Delta L)\).
3.5.2 Unified LLM Optimizations¶
OneTrans adopts FlashAttention-2 [dao2023flashattention2], mixed-precision training [micikevicius2018mixed], and activation recomputation [gruslys2016memory]. These optimizations reduce attention I/O, peak memory, and training cost, and they are especially natural to deploy because the whole model is already expressed as a Transformer backbone.
4. Experiments¶
The experiments are organized around five research questions:
- RQ1: Does a unified Transformer stack outperform encode-then-interaction baselines under comparable compute?
- RQ2: Which design choices matter most?
- RQ3: Do pyramid stacking, KV caching, FlashAttention, and mixed precision improve system efficiency?
- RQ4: Does OneTrans exhibit clear scaling-law behavior along sequence length, depth, and width?
- RQ5: Does online deployment improve business metrics under strict latency constraints?
4.1 Experimental Setup¶
4.1.1 Dataset¶
Offline evaluation uses a large industrial ranking dataset built from production logs under strict privacy compliance. All personally identifiable information is anonymized and hashed. Data are split chronologically, all features are snapshotted at impression time to avoid leakage, and labels such as click and order are aggregated within production-aligned windows.
| Metric | Value |
|---|---|
| Impressions (samples) | 29.1B |
| Users (unique) | 27.9M |
| Items (unique) | 10.2M |
| Daily impressions (mean ± std) | 118.2M ± 14.3M |
| Daily active users (mean ± std) | 2.3M ± 0.3M |
4.1.2 Tasks and Metrics¶
The paper evaluates two binary ranking tasks:
- CTR
- CVR
Performance is measured with AUC and UAUC, where UAUC is impression-weighted user-level AUC. Evaluation follows a next-batch protocol: for each mini-batch, the system first logs predictions in evaluation mode and then trains on the same batch. Daily AUC and UAUC are computed per day and macro-averaged across days.
For efficiency, the paper reports:
- Params: dense model parameters excluding sparse embeddings.
- TFLOPs: training compute in TFLOPs at batch size 2048.
4.1.3 Baselines¶
The baseline family follows the industrial encode-then-interaction paradigm. The paper starts with DCNv2 + DIN as a strong production baseline and then progressively strengthens either the feature-interaction or sequence-modeling component.
Feature-interaction scaling path:
- DCNv2 + DIN
- Wukong + DIN
- HiFormer + DIN
- RankMixer + DIN
Sequence-modeling scaling path, with RankMixer fixed:
- RankMixer + StackDIN
- RankMixer + LONGER
- RankMixer + Transformer
4.1.4 Hyperparameter Settings¶
Two main OneTrans configurations are reported.
- OneTrans_S uses 6 stacked blocks, hidden size \(d = 256\), and 4 attention heads, targeting about 100M parameters.
- OneTrans_L uses 8 layers with hidden size \(d = 384\).
Inputs use timestamp-aware fusion for multi-behavior sequences and Auto-Split for non-sequential features. The pyramid schedule linearly shrinks the number of sequential query tokens from 1190 to 12 for OneTrans_S, and from 1500 to 16 for OneTrans_L, rounding each layer to the nearest multiple of 32.
Optimization and infrastructure:
- Sparse embeddings use Adagrad with \(\beta_1 = 0.1\) and \(\beta_2 = 1.0\).
- Dense parameters use RMSProp with learning rate 0.005 and \(\alpha = 0.99999\).
- The system uses Pre-Norm and global gradient clipping.
- Per-GPU training batch size is 2048.
- Training runs on 16 H100 GPUs using data-parallel all-reduce.
4.2 RQ1: Performance Evaluation¶
Under the encode-then-interaction paradigm, independently strengthening feature interaction or sequence modeling improves the production baseline. But the gains from the unified design are significantly larger.
| Type | Model | CTR AUC | CTR UAUC | CVR AUC | CVR UAUC | Params (M) | TFLOPs |
|---|---|---|---|---|---|---|---|
| Base model | DCNv2 + DIN | 0.79623 | 0.71927 | 0.90361 | 0.71955 | 10 | 0.06 |
| Feature interaction | Wukong + DIN | +0.08% | +0.11% | +0.14% | +0.11% | 28 | 0.54 |
| Feature interaction | HiFormer + DIN | +0.11% | +0.18% | +0.23% | -0.20% | 108 | 1.35 |
| Feature interaction | RankMixer + DIN | +0.27% | +0.36% | +0.43% | +0.19% | 107 | 1.31 |
| Sequence modeling | RankMixer + StackDIN | +0.40% | +0.37% | +0.63% | -1.28% | 108 | 1.43 |
| Sequence modeling | RankMixer + LONGER | +0.49% | +0.59% | +0.47% | +0.44% | 109 | 1.87 |
| Sequence modeling | RankMixer + Transformer | +0.57% | +0.90% | +0.52% | +0.75% | 109 | 2.51 |
| Unified framework | OneTrans_S | +1.13% | +1.77% | +0.90% | +1.66% | 91 | 2.64 |
| Unified framework | OneTrans_L | +1.53% | +2.79% | +1.14% | +3.23% | 330 | 8.62 |
OneTrans_S already outperforms RankMixer + Transformer at a similar training-compute scale. OneTrans_L then pushes the gains further, which the paper interprets as evidence that unified modeling is more compute-efficient than scaling either component separately.
4.3 RQ2: Design Choices via Ablation Study¶
The ablation study uses OneTrans_S as the reference model and tests both input-design choices and block-design choices.
| Type | Variant | CTR AUC | CTR UAUC | CVR AUC | CVR UAUC | Params (M) | TFLOPs |
|---|---|---|---|---|---|---|---|
| Input | Group-wise Tokenizer | -0.10% | -0.30% | -0.12% | -0.10% | 78 | 2.35 |
| Input | Timestamp-agnostic Fusion | -0.09% | -0.22% | -0.20% | -0.21% | 91 | 2.64 |
| Input | Timestamp-agnostic Fusion without [SEP] | -0.13% | -0.32% | -0.29% | -0.33% | 91 | 2.62 |
| OneTrans Block | Shared parameters for all tokens | -0.15% | -0.29% | -0.14% | -0.29% | 24 | 2.64 |
| OneTrans Block | Full attention | +0.00% | +0.01% | -0.03% | +0.06% | 91 | 2.64 |
| OneTrans Block | Without pyramid stack | -0.05% | +0.06% | -0.04% | -0.42% | 92 | 8.08 |
The main conclusions are:
- Auto-Split tokenizer performs better than manual group-wise tokenization.
- Timestamp-aware fusion is better than ordering by behavior impact when timestamps are available.
- Learnable [SEP] tokens help the model separate multiple sequences when timestamp-agnostic fusion is used.
- Token-specific parameters for non-sequential tokens outperform sharing one projection across all token types.
- Causal attention performs about as well as full attention while preserving compatibility with caching and other system optimizations.
- Removing the pyramid stack greatly increases compute without producing meaningful quality gains, which suggests that most useful information can indeed be concentrated into a small tail of queries.
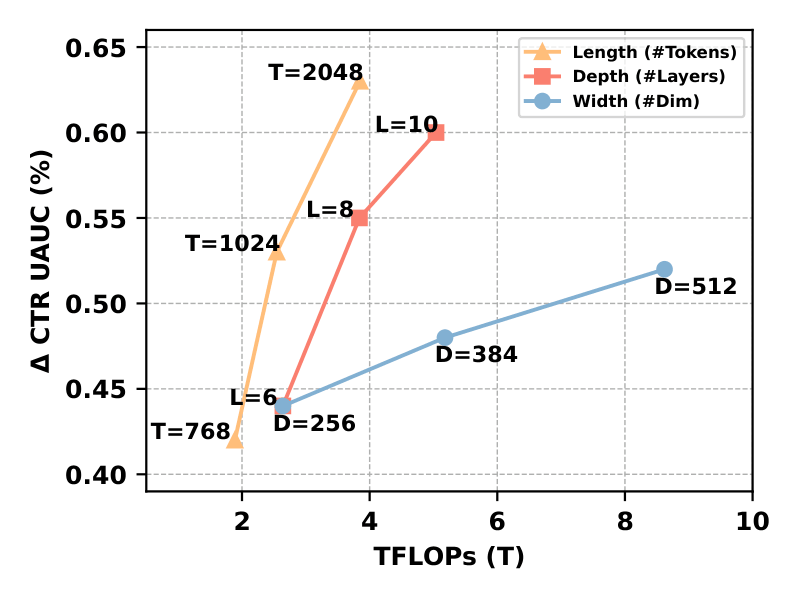
Figure 3a. Performance-compute trade-off: training FLOPs versus delta UAUC.
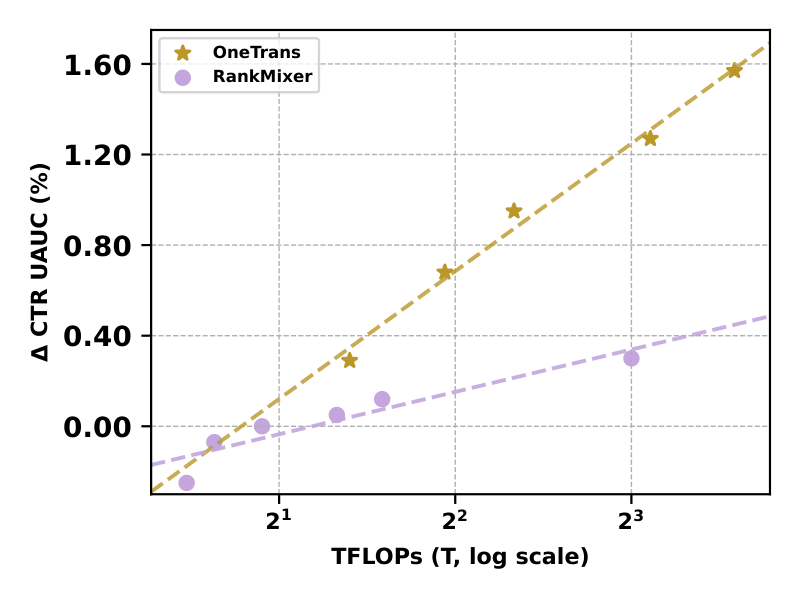
Figure 3b. Scaling law: delta UAUC versus FLOPs on a log scale.
4.4 RQ3: Systems Efficiency¶
To quantify the benefit of system-level optimizations, the paper compares each optimization against an unoptimized OneTrans_S baseline.
| Variant | Training Runtime | Training Memory | Inference Latency | Inference Memory |
|---|---|---|---|---|
| Unoptimized OneTrans_S | 407 ms | 53.13 GB | 54.00 ms | 1.70 GB |
| + Pyramid stack | -28.7% | -42.6% | -8.4% | -6.9% |
| + Cross-request KV caching | -30.2% | -58.4% | -29.6% | -52.9% |
| + FlashAttention | -50.1% | -58.9% | -12.3% | -11.6% |
| + Mixed precision with recomputation | -32.9% | -49.0% | -69.1% | -30.0% |
The findings are straightforward:
- Pyramid stacking reduces both training and serving cost by pruning sequential query tokens.
- Cross-request KV caching removes repeated sequence computation and significantly reduces both runtime and memory.
- FlashAttention provides especially strong training-side improvements.
- Mixed precision with recomputation gives the largest online serving gains.
These results are used to justify scaling to OneTrans_L while still keeping production latency within budget.
4.5 RQ4: Scaling-Law Validation¶
The paper studies scaling along three axes:
- Length: input token sequence length.
- Depth: number of stacked blocks.
- Width: hidden-state dimension.
It reports that increasing sequence length gives the largest gains, likely because additional behavior evidence is especially valuable in ranking. Between depth and width, depth generally provides better quality improvements, because deeper stacks can model higher-order interactions and richer abstractions. Width is still attractive for parallel efficiency, so the right choice depends on the deployment budget.
The paper also compares the scaling slope of OneTrans against a RankMixer + Transformer baseline whose RankMixer side is scaled up to 1B parameters. Both show a roughly log-linear trend when plotting delta UAUC against training FLOPs, but OneTrans has a steeper slope. The interpretation is that OneTrans is more parameter-efficient and compute-efficient because it scales a unified backbone instead of mostly widening a separate interaction module.
An additional efficiency comparison with the old production baseline is reported below.
| Metric | DCNv2 + DIN | OneTrans_L |
|---|---|---|
| TFLOPs | 0.06 | 8.62 |
| Params (M) | 10 | 330 |
| MFU | 13.4 | 30.8 |
| Inference Latency (p99, ms) | 13.6 | 13.2 |
| Training Memory (GB) | 20 | 32 |
| Inference Memory (GB) | 1.8 | 0.8 |
Even though OneTrans_L is far larger than DCNv2 + DIN, its optimized serving latency remains comparable and its inference memory is actually lower, which the paper treats as a key production result.
4.6 RQ5: Online A/B Tests¶
The online study evaluates OneTrans_L in two industrial scenarios:
- Feeds
- Mall
Traffic is split at the user or account level using hashing and randomization. Both control and treatment use the same 1.5 years of production data. The control is RankMixer + Transformer, about 100M neural-network parameters and no sequence KV caching. The treatment is OneTrans_L with the serving optimizations described earlier.
Reported metrics are click per user, order per user, GMV per user, and end-to-end p99 latency. Relative deltas are measured against the control.
| Scenario | Click/u | Order/u | GMV/u | Latency (p99) |
|---|---|---|---|---|
| Feeds | +7.737% | +4.351% | +5.685% | -3.91% |
| Mall | +5.143% | +2.577% | +3.670% | -3.26% |
The paper also reports a +0.7478% increase in user Active Days and a +13.59% gain in cold-start product order per user. Overall, the results indicate that the unified backbone improves business metrics while also reducing serving latency relative to a strong non-unified production baseline.
5. Conclusion¶
OneTrans is presented as a unified Transformer backbone for industrial ranking that replaces the conventional encode-then-interaction architecture with a single computation graph. A unified tokenizer converts both sequential and non-sequential attributes into one token sequence. Mixed Transformer blocks then jointly perform sequence modeling and feature interaction by using shared parameters for homogeneous sequential tokens and token-specific parameters for heterogeneous non-sequential tokens. Pyramid stacking, cross-request KV caching, FlashAttention, and mixed precision make this unified stack practical at scale. Across large-scale offline evaluation and online deployment, the paper reports near log-linear scaling behavior, significant improvements in CTR and CVR quality, and measurable lifts in real business KPIs while maintaining production-grade latency.