The Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation¶
Condensed from the LaTeX source under arXiv-2604.04976.
Converted figures now live under img/taac2025/ and are referenced directly from this markdown file.
Authors¶
Junwei Pan, Wei Xue, Chao Zhou, Xing Zhou, Lunan Fan, Yanbo Wang, Haoran Xin, Zhiyu Hu, Yaozheng Wang, Fengye Xu, Yurong Yang, Xiaotian Li, Junbang Huo, Wentao Ning, Yuliang Sun, Chengguo Yin, Jun Zhang, Shudong Huang, Lei Xiao, Huan Yu, Irwin King, Haijie Gu, and Jie Jiang.
Affiliations:
- Tencent Inc.
- The Chinese University of Hong Kong
Abstract¶
This paper reports the official 2025 Tencent Advertising Algorithm Challenge, which framed advertising recommendation as all-modality generative recommendation. The competition released two de-identified industrial datasets, TencentGR-1M and TencentGR-10M, where user histories contain sparse collaborative IDs, behavior types, and precomputed text/image embeddings rather than raw creatives.
The task is next-item prediction from a large ad candidate pool. The preliminary round focuses on next-click prediction, while the second round adds conversion events and weights conversions more heavily in evaluation. The official baseline uses a causal Transformer with InfoNCE training and ANN retrieval, and the paper summarizes several top solutions built around action conditioning, Semantic ID construction, larger negative banks, and Transformer scaling.
Keywords¶
- Generative Recommendation
- Sequential Recommendation
- Multi-modal Learning
- Advertising
- Competition Dataset
- Semantic ID
1. Why This Paper Matters¶
Most public generative recommendation datasets are medium-scale e-commerce or news corpora. TencentGR is important because it exposes a closer industrial advertising shape:
- large candidate pools: 660K ads in TencentGR-1M and 3.64M ads in TencentGR-10M;
- multi-behavior histories: exposures and clicks in the preliminary track, exposures, clicks, and conversions in the final track;
- all-modality item representation: hashed sparse IDs plus six text/image embedding families;
- retrieval-style evaluation: HR@10 and NDCG@10 rather than pointwise CTR metrics;
- competition-tested modeling ideas from thousands of teams.
For TAAC 2026 work, the paper is especially useful as a bridge between classic CTR modeling and sequence-generation-style retrieval.
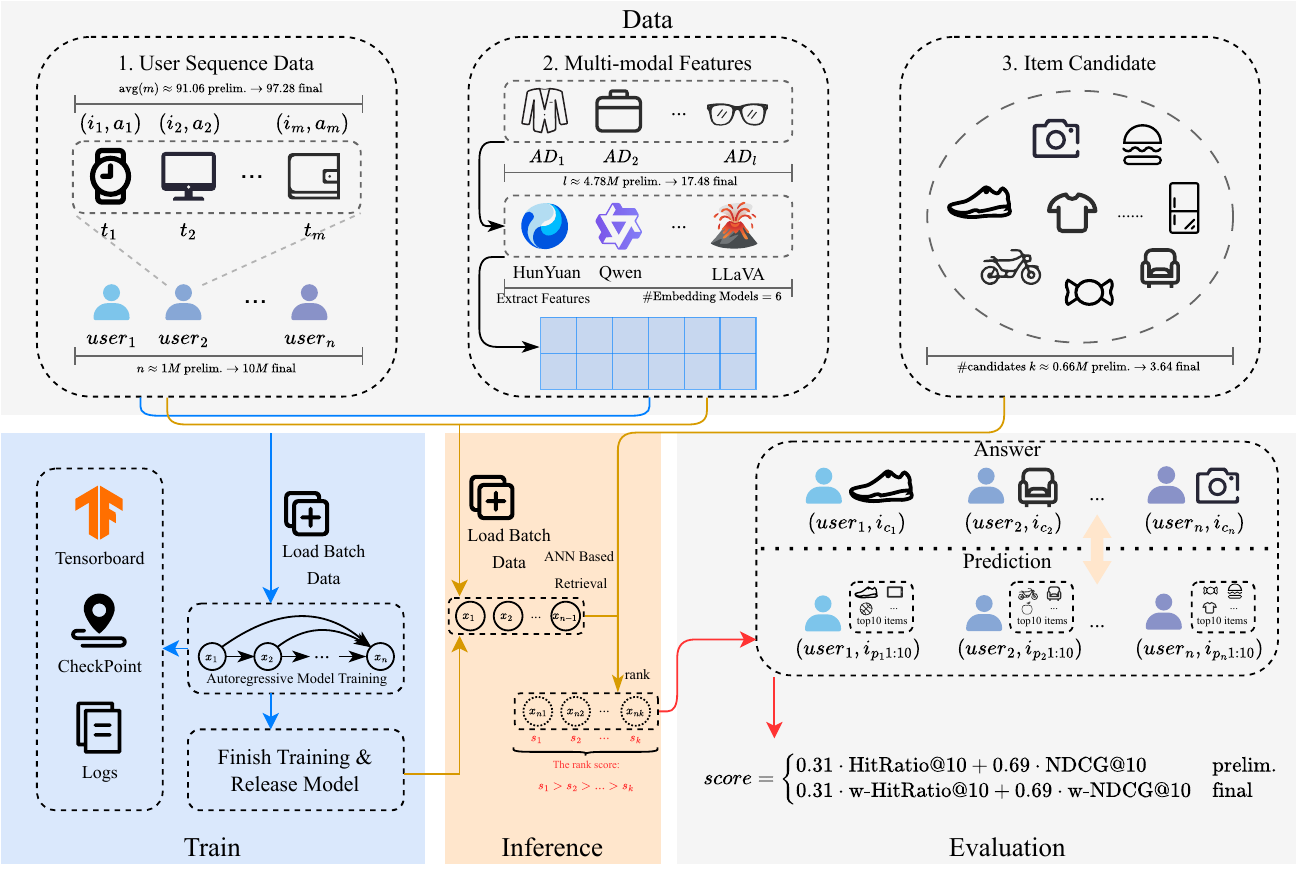
Figure 1. Overall competition framework from the arXiv source. The workflow contains user sequence data, multi-modal feature files, candidate items, autoregressive training, inference, and official evaluation.
2. Challenge Setting¶
The challenge observes a chronological sequence for each user:
where \(x_u\) is a user-profile token and \(x_{u,t}\) is an ad interaction token. Each item token contains categorical ad features, an action signal, and multi-modal item embeddings:
Given a prefix of the sequence, the model must retrieve the next ad from a global candidate set.
Rounds¶
| Round | Dataset | Target | Candidate pool | Advancement |
|---|---|---|---|---|
| Preliminary | TencentGR-1M | next clicked ad | 660K ads | top 50 teams advance |
| Second round | TencentGR-10M | next clicked or converted ad | 3,637,720 ads | top 20 teams enter final |
| On-site final | TencentGR-10M | same as second round | private evaluation | 75% leaderboard + 25% committee review |
The competition explicitly prohibited model ensembling and required generative recommendation ideas, such as autoregressive sequence modeling or generative Semantic ID construction, rather than purely discriminative ranking submissions.
3. TencentGR Datasets¶
Both datasets are built from de-identified Tencent Ads logs. The data removes personally identifiable information and raw ad creatives; participants receive hashed IDs and extracted embeddings instead.
| Statistic | TencentGR-1M | TencentGR-10M |
|---|---|---|
| Users | 1,001,845 | 10,139,575 |
| Ads | 4,783,154 | 17,487,676 |
| Max sequence length | 100 | 100 |
| Average sequence length | 91.06 | 97.29 |
| Candidate ads | 660,000 | 3,637,720 |
| Exposure share | 90.19% | 94.63% |
| Click share | 9.81% | 2.85% |
| Conversion share | - | 2.52% |
Preliminary Track Construction¶
TencentGR-1M samples users with at least one click in the answer window. For each user, the first clicked ad after the reference time is attributed back to its triggering impression, and that impression becomes the prediction target. The history contains all exposures and clicks before that target exposure.
Final Track Construction¶
TencentGR-10M scales the task by roughly an order of magnitude and adds conversion attribution. If a conversion can be found after the reference time, it is associated with the click and then the underlying impression. Otherwise, the first click is used as in the preliminary round. Conversions appear both inside histories and as target types.
Multi-modal Features¶
The released creative representation contains six precomputed embedding families:
| Emb ID | Model | Modality | Parameters | Dimension |
|---|---|---|---|---|
| 81 | Bert-finetune | text | 0.3B | 32 |
| 82 | Conan-embedding-v1 | text | 0.3B | 1,024 |
| 83 | gte-Qwen2-7B-instruct | text | 7B | 3,584 |
| 84 | Hunyuan-mm-7B-finetune | image | 7B | 4,096 / 32 |
| 85 | QQMM-embed-v1 | image | 8B | 3,584 |
| 86 | UniME-LLaVA-OneVision-7B | image | 8B | 3,584 |
The Bert and Hunyuan embeddings are fine-tuned with real collaborative data and contrastive learning; the other embedding families are used directly from their pretrained encoders.
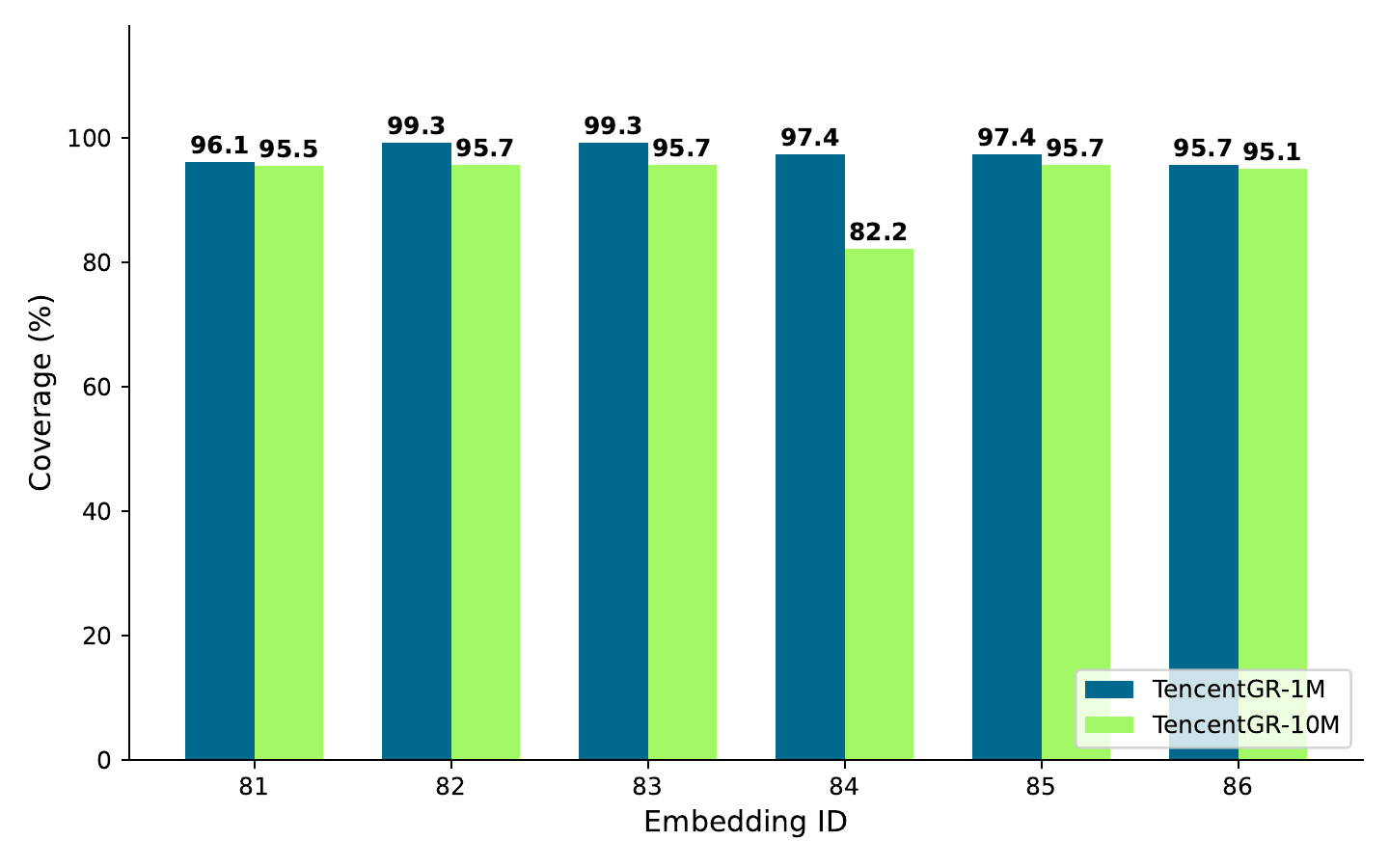
Figure 2. Coverage of the six multi-modal embedding families on TencentGR-1M and TencentGR-10M.
4. Official Baseline¶
The released baseline is a retrieval-oriented generative recommendation pipeline.
Feature Encoding¶
Each sparse field owns an embedding table. For user-profile and item-interaction tokens, field embeddings are concatenated and projected through a small MLP. Item tokens additionally concatenate the provided continuous multi-modal embeddings before projection.
Backbone¶
The model prepends the user token, adds learnable positional embeddings, and feeds the sequence to a causal Transformer. The hidden state at each position represents the user state for predicting the next item.
The published baseline configuration is deliberately small:
| Component | Setting |
|---|---|
| Transformer layers | 1 |
| Hidden dimension | 32 |
| Attention heads | 1 |
| Dropout | 0.2 |
| Max sequence length | 101 including user token |
| Optimizer | Adam |
| Learning rate | 0.001 |
| Negative sampling | 1 negative per positive target |
Training Objective¶
The baseline uses InfoNCE. For a user state and positive next item \(i^+\), negatives are sampled from the global item pool:
In the second round, the objective is weighted by action type so conversion targets can contribute more heavily.
Inference¶
Inference decouples user embedding and item retrieval:
- encode the user history with the Transformer and take the final hidden state as the user embedding;
- precompute candidate item embeddings with the same item encoder;
- build a Faiss ANN index and retrieve top-\(K\) items with the user embedding as query.
This matters because the official metrics evaluate retrieval quality over hundreds of thousands to millions of candidate ads.
5. Evaluation Protocol¶
Preliminary Round¶
The preliminary round treats only clicks as relevant. The official leaderboard score is:
The coefficients were calibrated on internal baselines so the two metrics contribute at comparable scale.
Second Round¶
The second round uses weighted metrics. Relevance depends on the action type:
where \(\alpha=2.5\). The leaderboard keeps the same combination shape, but uses weighted HR@10 and weighted NDCG@10.
6. Top Solution Patterns¶
The challenge attracted more than 8,440 registered participants and about 2,800 teams. The paper summarizes the top three teams plus the Technical Innovation Award winner.
| Team | Core architecture | Key ideas |
|---|---|---|
| 1st place | dense Qwen-based autoregressive model | per-position action conditioning, gated fusion, FiLM, attention bias, Fourier time features, RQ-KMeans Semantic ID, random-\(k\) regularization, Muon + AdamW, large negative banks |
| 2nd place | encoder-decoder model | gated MLP encoders, user-item GNN context, SASRec-style decoder with 2048 hidden size, 8 layers, 8 heads, SVD + RQ-KMeans Semantic ID, PinRec-style next-action conditioning, exposure pretraining then click/conversion finetuning |
| 3rd place | decoder-only Transformer | sparse user/item features, rich time signals, next-action conditioning, InfoNCE, AMP, static graph compilation, systematic scaling of negatives, model size, and item-ID embedding dimension |
| Technical Innovation Award | decoder-only joint retrieval-ranking generator | joint Semantic ID generation and action prediction, FlashAttention, SwiGLU, RMSNorm, RoPE, DeepSeek-V3-style MoE, collaborative item embeddings, collision resolution for Semantic ID codes, grouped GEMM and KV cache acceleration |
Across these solutions, three design choices recur: causal Transformer backbones, contrastive retrieval objectives, and explicit action conditioning.
7. Takeaways for TAAC 2026¶
Treat Action Type as a Modeling Signal¶
The strongest teams did not leave exposure, click, and conversion as only labels. They injected action type into token representation or generation conditioning. If the 2026 data continues to expose multi-behavior signals, action-conditioned sequence modeling should be treated as a first-class design axis.
Align the Objective With Retrieval¶
The official baseline and top solutions optimize InfoNCE and retrieve with ANN indexes. This is a different optimization target from pointwise BCE ranking and is better aligned with HR@K/NDCG@K candidate retrieval.
Explore Discrete Item Representations¶
RQ-KMeans Semantic ID appears repeatedly because it converts high-dimensional multi-modal embeddings into discrete token sequences that fit generative modeling. This is a natural direction for using upstream text/image embeddings without passing every raw vector through the sequence backbone.
Scaling Is Not Optional¶
The third-place solution observed continuing gains when scaling negatives up to 380K. The official baseline's one-negative setup is intentionally small, leaving substantial room in negative-bank design, item embedding dimension, Transformer capacity, and batch construction.
Time Features Need More Than Position IDs¶
Top teams used absolute timestamps, relative gaps, session structure, and periodic Fourier features. For advertising logs, elapsed time and conversion delay can carry signal that a simple learned position embedding may miss.
8. Resources¶
- arXiv: https://arxiv.org/abs/2604.04976
- arXiv source: https://arxiv.org/src/2604.04976
- Official website: https://algo.qq.com/2025
- TencentGR-1M: https://huggingface.co/datasets/TAAC2025/TencentGR-1M
- TencentGR-10M: https://huggingface.co/datasets/TAAC2025/TencentGR-10M
- Baseline code: https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025
References¶
- Pan et al. The Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation. arXiv 2604.04976, 2026.
- Badrinath et al. PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems. arXiv 2504.10507, 2025.
- Zhai et al. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. ICML 2024.
- Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023.
- Douze et al. The Faiss Library. arXiv 2401.08281, 2024.