HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction¶
Converted from the LaTeX source under arXiv-2601.12681v2.
Converted figures now live under img/hyformer/ and are referenced directly from this markdown file.
Authors¶
- Yunwen Huang
- Shiyong Hong
- Xijun Xiao
- Jinqiu Jin
- Xuanyuan Luo
- Zhe Wang
- Zheng Chai
- Shikang Wu
- Yuchao Zheng
- Jingjian Lin
Notes:
*in the original paper marks equal contribution.daggerin the original paper marks corresponding authors.
Affiliations:
- ByteDance AML, Beijing, China
- ByteDance Search, Beijing, China
- ByteDance AML, Hangzhou, China
Abstract¶
Industrial large-scale recommendation models (LRMs) face the challenge of jointly modeling long-range user behavior sequences and heterogeneous non-sequential features under strict efficiency constraints. However, most existing architectures employ a decoupled pipeline: long sequences are first compressed with a query-token based sequence compressor like LONGER, followed by fusion with dense features through token-mixing modules like RankMixer, which thereby limits both the representation capacity and the interaction flexibility. This paper presents HyFormer, a unified hybrid transformer architecture that tightly integrates long-sequence modeling and feature interaction into a single backbone. From the perspective of sequence modeling, we revisit and redesign query tokens in LRMs, and frame the LRM modeling task as an alternating optimization process that integrates two core components: Query Decoding which expands non-sequential features into Global Tokens and performs long sequence decoding over layer-wise key-value representations of long behavioral sequences; and Query Boosting which enhances cross-query and cross-sequence heterogeneous interactions via efficient token mixing. The two complementary mechanisms are performed iteratively to refine semantic representations across layers. Extensive experiments on billion-scale industrial datasets demonstrate that HyFormer consistently outperforms strong LONGER and RankMixer baselines under comparable parameter and FLOPs budgets, while exhibiting superior scaling behavior with increasing parameters and FLOPs. Large-scale online A/B tests in high-traffic production systems further validate its effectiveness, showing significant gains over deployed state-of-the-art models. These results highlight the practicality and scalability of HyFormer as a unified modeling framework for industrial LRMs.
CCS Concepts¶
- Information systems - Recommender systems
Keywords¶
- Feature Interaction
- Large Recommendation Models
- Long Sequence Modeling
- Scaling Law
1. Introduction¶
Modern industrial large-scale recommendation models (LRMs) operate in increasingly complex environments, where accurate prediction relies on jointly modeling long-range user behavior histories and rich heterogeneous features, including user profiles, contextual signals, and cross features. As user engagement grows over extended time horizons and feature spaces continue to expand, effectively integrating long sequential signals with high-dimensional non-sequential information has become a central challenge for large-scale recommendation and search systems.
To address this challenge, recent industrial architectures have largely converged on a separated scaling paradigm that combines long sequence modeling [Xu_2025; Zivic_2024; borisyuk2024lirank] with feature interaction [gui2023hiformer; yu2025hhfthierarchicalheterogeneousfeature; xu2025store; khrylchenko2025scaling]. Within this paradigm, long user behavior sequences are encoded by dedicated sequence transformers to capture temporal dependencies and user interests, and the compressed sequence token(s) are mixed with other heterogeneous features through token-mixing or interaction modules to enable cross-feature reasoning. This "Long Sequence Modeling, Then Heterogeneous Feature Interaction" pipeline has proven effective and has become the dominant design choice for scaling up modern industrial LRMs. Despite strong empirical performance, this prevailing paradigm fundamentally enforces a compressed, late-fusion, and unidirectional interaction pattern. As sequence lengths and model capacities continue to increase, this two-stage design reveals fundamental limitations that restrict both modeling expressiveness and scalability.
- Sequence transformers in existing architectures often rely on overly simplified query representations [zhou2018deep; zhou2019deep; feng2019deep] during sequence compression. In practice, the query tokens used to aggregate long behavior sequences are usually derived from a limited subset of candidate-related or global features, constraining the amount of contextual information that can be leveraged when modeling long-term user interests. However, directly increasing the number of query tokens would lead to a significant degradation in serving efficiency under KV-Cache and M-Falcon mechanisms [zhai2024actions; chai2025longerscalinglongsequence].
- Interactions between sequence-compressed tokens and heterogeneous non-sequential tokens typically occur only at late stages of the model. Under the current paradigm, cross-feature reasoning is deferred until after sequence compression, leading to shallow and implicit interactions between different token types. This delayed fusion limits the model's ability to capture fine-grained dependencies across multiple behavior sequences and heterogeneous feature groups, and prevents early-layer representations from benefiting from cross-domain contextual information.
- Since interaction modules operate only on compressed sequence representations, increasing model capacity or sequence length primarily improves isolated components rather than enhancing joint representations. As a result, scaling up depth or parameters leads to a lower scaling efficiency, where performance improvements increase at a slower rate with respect to additional computational budgets, as computation is less effectively translated into richer joint representations.
These limitations motivate a fundamental rethinking of how long-range sequence modeling and heterogeneous feature interaction should be integrated. Rather than treating sequence encoding and token mixing as two loosely coupled stages, a unified modeling framework is needed to enable deeper, earlier, and bidirectional interactions between sequential and non-sequential signals.
In this paper, we propose HyFormer, a hybrid transformer architecture that unifies sequence modeling and feature interaction within a single backbone. HyFormer introduces a set of global tokens that serve as a shared semantic interface between long behavior sequences and heterogeneous features. Through a stacked design, HyFormer alternates between two lightweight yet expressive mechanisms. The Query Decoding module uses global query tokens to attend over layer-wise key-value representations of long behavioral sequences, allowing global context to directly shape sequence representations. The Query Boosting module further strengthens cross-query and cross-sequence interactions via efficient token mixing, progressively enriching semantic representations across layers. This design enables a bidirectional flow of information between sequence modeling and feature interaction components, overcoming the limitations of traditional decoupled pipelines. Extensive experiments on billion-scale industrial datasets demonstrate that HyFormer consistently outperforms strong sequence-based and token-mixing baselines under comparable parameter and FLOPs budgets. Moreover, HyFormer exhibits superior scaling behavior with respect to model FLOPs and parameters, and achieves significant gains in large-scale online A/B tests deployed in high-traffic production systems.
In summary, this paper makes the following contributions:
- We identify fundamental limitations of the prevailing decoupled sequence modeling and feature interaction paradigm in large-scale industrial recommender systems, and analyze how its unidirectional and late-fusion design constrains modeling capacity and scalability.
- We propose HyFormer, a unified hybrid transformer architecture that enables bidirectional, layer-wise interaction between long-range behavioral sequences and heterogeneous features through Query Decoding and Query Boosting, achieving state-of-the-art performance and scalability in real-world industrial settings.
- We empirically verify the effectiveness and its superior scaling performance of the proposed models on a billion-scaled industrial dataset. Currently, HyFormer has been fully deployed at Bytedance, serving billions of users each day.
2. Related Work¶
2.1 Traditional Recommendation Paradigms¶
Modern industrial LRMs are typically built upon two major components: behavior-sequence modeling and feature-interaction networks. In this paradigm, user behavior histories are first encoded by dedicated sequence models, whose outputs are then consumed by downstream interaction modules together with heterogeneous non-sequential features. Recent industrial systems have substantially advanced the scalability of sequence modeling along this direction. Methods such as SIM [qi2020searchbasedusermodelinglifelong], ETA [chen2022efficient], TWIN [chang2023twintwostagenetworklifelong; Si_2024], TransAct [Xia_2023], and LONGER [chai2025longerscalinglongsequence] extend sequence encoders to hundreds or thousands of events through efficient attention mechanisms, hierarchical aggregation, KV caching, and serving-friendly designs. These works demonstrate clear power-law scaling trends in modeling long-range user behaviors under large-scale traffic, while largely preserving a two-stage architecture that decouples sequence encoding from feature interaction.
On the feature-interaction side, early models such as DeepFM [guo2017deepfmfactorizationmachinebasedneural], xDeepFM [Lian_2018], and DCNv2 [Wang_2021] model low-order or bounded-degree feature crosses at scale but suffer from diminishing returns as interaction depth increases. Recent scaling studies like Wukong [zhang2024wukong] and RankMixer [zhu2025rankmixerscalingrankingmodels] highlight that cross-module expansion becomes a key driver of industrial performance. These models represent the current state of large-scale feature-interaction design, yet the interaction stack and sequence encoder remain loosely coupled in most production pipelines, resulting in late fusion and preventing unified optimization across heterogeneous signals.
2.2 Unified Recommendation Architectures¶
To reduce the fragmentation between sequence modeling and feature interaction, recent studies explore unified architectures that handle heterogeneous signals within a single backbone. Hierarchical generative architectures such as HSTU [zhai2024actionsspeaklouderwords] represent a unified recommendation paradigm by performing sequence transduction conditioned on contextual and candidate signals. InterFormer [zeng2025interformereffectiveheterogeneousinteraction] bridges the gap between sequence encoders and interaction networks by introducing learnable interaction tokens that enable bidirectional signal exchange. MTGR [Han_2025] further pushes unification by reorganizing user, behavior, real-time, and candidate features into heterogeneous tokens and encoding them with a shared Transformer-style backbone, enabling both sequence information and cross features to be modeled coherently. Following MTGR, OneTrans [zhang2025onetransunifiedfeatureinteraction] shares a similar direction by using a single Transformer to jointly capture sequence dependencies and high-order feature interaction, while simplifying the Transformer structure with a pyramid-compression style. This work can be regarded as a simplified version compared to MTGR.
As MTGR [Han_2025] and OneTrans [zhang2025onetransunifiedfeatureinteraction] simply increase the number of query tokens as the number of all the non-sequence tokens, it would be readily observed a significant drop in serving efficiency in practice. Besides, a unified transformer structure for modeling feature interaction is generally insufficient in industrial-scale LRMs [zhu2025rankmixerscalingrankingmodels]. Overall, unified architectures represent a step toward dissolving the long-standing separation between sequence models and feature-interaction stacks, though achieving full unification with minimal architectural overhead remains an open challenge.
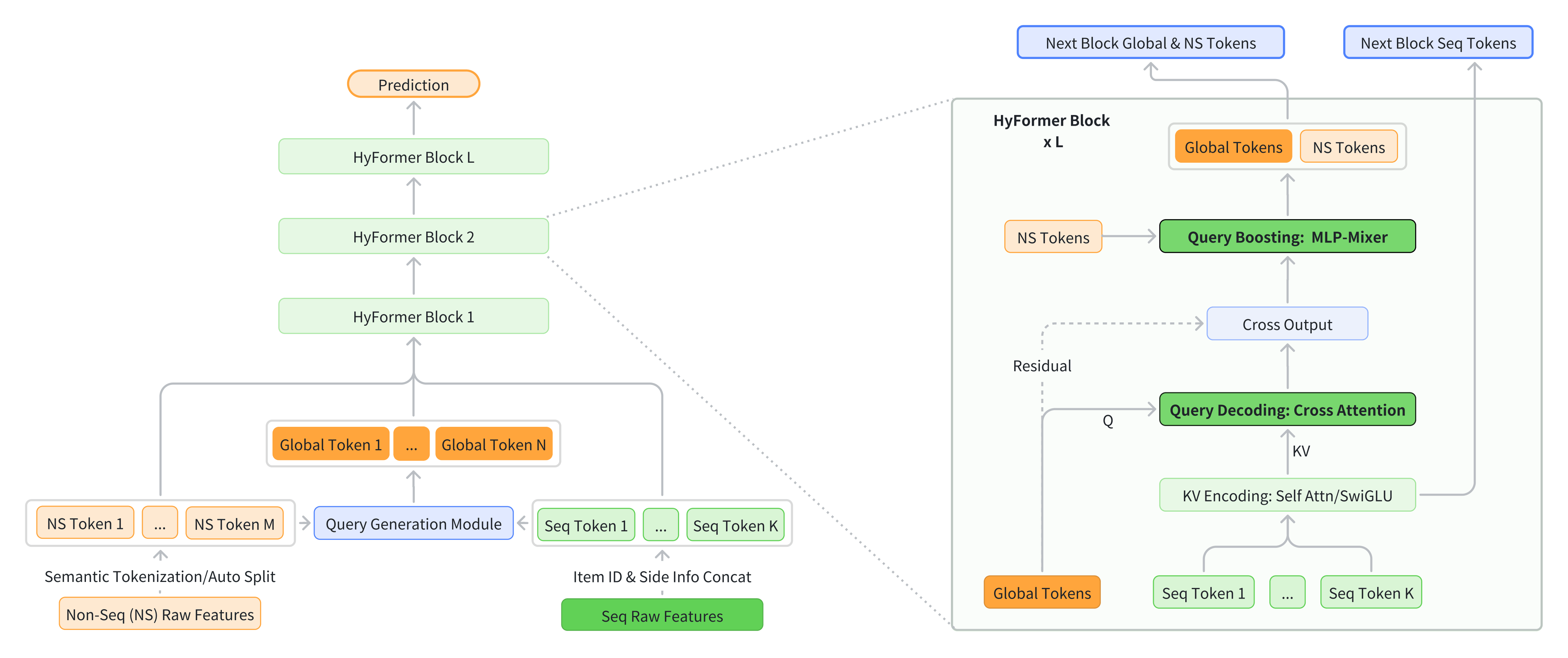
Figure 1. Overview of the proposed HyFormer architecture. The new architecture introduces global tokens that are derived from the original candidate item in sequence modeling, and revisits the roles of long-sequence modeling and feature interaction by boosting the query capacity of long-sequence via MLP-Mixer-based feature interaction. It frames the LRM modeling task as an alternating optimization process through the alternation of Query Decoding and Query Boosting modules.
3. Methodology¶
3.1 Problem Statement¶
Let \(\mathcal{U}\) and \(\mathcal{I}\) denote the user and item spaces. For a user \(u \in \mathcal{U}\), denote the raw behavioral history as \(S = \lbrack i^{(u)}_1, \ldots, i^{(u)}_K \rbrack\) with each \(i^{(u)}_t \in \mathcal{I}\), and let \(u\) represent the accompanying non-sequential descriptors such as profile attributes, contextual signals, and cross features. Given a candidate item \(v \in \mathcal{I}\), the goal is to estimate the probability that user \(u\) engages with item \(v\):
where \(y \in \{0,1\}\) indicates whether the interaction occurs.
The model parameters are learned from historical data \(\mathcal{D} = \{(S, u, v, y)\}\) by minimizing the standard binary cross-entropy objective:
where \(\hat{y} = f_{\theta}(S, u, v)\) denotes the predicted engagement probability produced by the LRM.
3.2 Overall Framework¶
Traditional LRM architectures generally adopt a pipelined design by performing sequence modeling like LONGER [chai2025longerscalinglongsequence] first, and the query token containing the compressed sequence information is then used for subsequence feature interaction like RankMixer [zhu2025rankmixerscalingrankingmodels]. As discussed before, this separate pipeline generally results in an insufficient modeling for both sequence modeling and heterogeneous feature interaction. To overcome the limitation, this work proposes a unified hybrid framework that jointly models non-sequential (NS) tokens and long behavioral sequences through a stack of HyFormer layers.
The overall architecture of HyFormer is presented in Figure 1. Each HyFormer layer integrates two complementary mechanisms:
- Query Decoding, which expands non-sequential and sequential features into multiple semantic global tokens via MLP-based query generation and performs cross-attention over long-sequence key/value pairs, enabling global information to directly shape the representation of sequence tokens.
- Query Boosting, which applies MLP-Mixer-style token mixing to strengthen interactions among decoded queries and non-sequence tokens.
By tightly coupling global heterogeneous-feature mixing with efficient long-sequence modeling, the proposed framework achieves richer heterogeneous interactions, deeper utilization of sequential structure, and more favorable performance and computation cost compared with existing separate pipelined architectures.
3.3 Query Generation¶
3.3.1 Input Tokenization¶
Following the tokenization strategy in RankMixer [zhu2025rankmixerscalingrankingmodels], input tokens can be organized either by semantic grouping or by automatic splitting. Semantic grouping partitions tokens according to their intrinsic meanings, such as user, context, or behavior semantics, while auto-split flattens all features into a single embedding and applies uniform splitting without explicit semantic distinctions. In practice, given the clear semantic roles of input features in this setting, HyFormer adopts semantic grouping to preserve structured inductive bias and improve interpretability.
3.3.2 Query Generation¶
The Query Generation module converts heterogeneous non-sequential features into semantic query tokens used for decoding long behavioral sequences. All non-sequential feature vectors \(F_1, F_2, \ldots, F_M \in \mathbb{R}^{1 \times D}\) are concatenated and mapped through a lightweight feed-forward network. In addition, a global sequence-level summary is obtained via pooling over the behavioral sequence representations and treated as an additional shared input, analogous to non-sequential features.
The queries are generated by combining non-sequential features with the pooled sequence summary through a lightweight projection:
where
To maintain serving efficiency, the module supports feature selection and optional query compression, keeping the number of generated queries stable while preserving sufficient representational capacity for downstream decoding.
In deeper HyFormer layers, queries are not regenerated through MLPs. Instead, each layer reuses the queries from the previous layer, effectively using deeper cross-attention outputs as updated queries to interrogate the long sequence with progressively richer semantics.
3.4 Query Decoding¶
The Query Decoding module is responsible for transforming non-sequential features into semantic queries and extracting target-aware information from long behavioral sequences through cross attention. With the layer-wise key-value representations of the long sequence produced by the Sequence Representation Encoding module, the Query Decoding module decodes the key/value representation with the multiple query tokens from the Query Generation Module via multi-query cross attention.
3.4.1 Sequence Representation Encoding¶
HyFormer supports multiple sequence encoding strategies with different capacity-efficiency trade-offs. Given the behavioral sequence \(S\), each strategy produces layer-wise key-value representations \((K^{(s)}_{l}, V^{(s)}_{l})\) for subsequent decoding.
(i) Full Transformer Encoding [vaswani2017attention]
At the highest modeling capacity, a standard Transformer encoder is applied:
which captures fine-grained interactions and long-range dependencies via full self-attention.
(ii) LONGER-style Efficient Encoding [chai2025longerscalinglongsequence]
To improve efficiency for long sequences, full self-attention is replaced by cross-attention between a compact short sequence and the full history:
where \(S_{\text{short}}\) is a compact short sequence with length \(L_H \ll L_S\). Here, \(S_{\text{short}}\) serves as the query, while \(S\) is used as both keys and values. This formulation reduces the computational complexity from \(\mathcal{O}(L_S^2)\) to \(\mathcal{O}(L_H L_S)\).
(iii) Decoder-style Lightweight Encoding
For latency-critical scenarios, sequence representations are transformed using attention-free feed-forward operations:
trading contextual capacity for minimal computational cost.
Across all variants, the resulting representations are linearly projected to obtain layer-specific key-value states:
Key-value states are recomputed at each layer, allowing sequence features to evolve jointly with decoder depth while supporting flexible deployment configurations.
3.4.2 Query Decoding via Cross-Attention¶
Given the sequence-specific query tokens and the corresponding layer-wise key-value representations, HyFormer performs Query Decoding through cross-attention. For each behavioral sequence \(S\) at layer \(l\), the decoded query representations are obtained as:
where \(\mathrm{CrossAttn}(\cdot)\) denotes a standard multi-head cross-attention operation, and \(Q_{(l)} \in \mathbb{R}^{N \times D}\) represents the query token used at layer \(l\).
This decoding step allows global, non-sequential features to directly attend to long behavioral sequences, injecting contextual signals into the sequence-aware query representations. The decoded query \(\widetilde{Q}_{(l)}\) are then used as the semantic interface for subsequent interaction and boosting modules.
3.5 Query Boosting¶
The Query Boosting module enhances query representations before they are fed into the subsequent cross-attention layer. After the decoding step, the queries already encode sequence-aware information, but their interactions with static non-sequential heterogeneous features remain underexplored. Query Boosting addresses this limitation by explicitly mixing information across query tokens and injecting additional non-sequence-feature signals.
With the decoded output, the unified query representation is defined as:
where \(T = N + M\), \(\widetilde{Q}_{(l)} \in \mathbb{R}^{N \times D}\) denotes the set of decoded query tokens obtained at layer \(l\), and the remaining \(M\) tokens correspond to non-sequential feature embeddings.
Specifically, the boosting module applies an MLP-Mixer-style [tolstikhin2021mlp] lightweight token-mixing operation inspired by RankMixer [zhu2025rankmixerscalingrankingmodels] to enrich the decoded queries. Each query token \(q_t \in Q\) is first partitioned into \(T\) channel subspaces:
For each subspace index \(h \in \{1,\ldots,T\}\), MLP-Mixer aggregates information from all token positions by concatenating the corresponding subspaces:
Collecting all mixed tokens yields the token-mixed representation:
The mixed queries are further refined by a lightweight per-token feed-forward module:
where \(\mathrm{PerToken\text{-}FFN}(\cdot)\) applies an independent feed-forward transformation to each query token, enabling subspace-specific refinement while preserving linear computational complexity.
Finally, a residual connection is applied to stabilize optimization and preserve the original decoded semantics:
The boosted queries are then passed to the next HyFormer layer, allowing deeper layers to interrogate long behavioral sequences with progressively richer and more expressive representations.
3.6 HyFormer Module¶
The HyFormer module is constructed by stacking multiple layers, each consisting of a Query Decoding block followed by a Query Boosting block. At each layer, semantic queries interact with the long behavioral sequence via cross-attention, and the resulting sequence-aware representations are further refined to serve as inputs to deeper layers.
Formally, at layer \(l\), the Query Decoding block takes the incoming global queries \(Q^{(l-1)}\) and performs cross-attention over the layer-wise key-value representations \((K^{(l)}, V^{(l)})\) derived from the long sequence:
The decoded queries \(\widehat{Q}^{(l)}\) are then concatenated with the non-sequential tokens and passed to the Query Boosting block, which applies a lightweight token-wise transformation to enrich the query representations:
By stacking multiple such layers, HyFormer progressively refines the semantic queries, enabling deeper layers to abstract the long sequence with increasingly expressive representations. The output of the top HyFormer layer is fed into downstream MLPs for final predictions, enabling efficient and flexible integration of heterogeneous non-sequential features with long behavioral sequences in LRMs.
3.7 Multi-Sequence Modeling¶
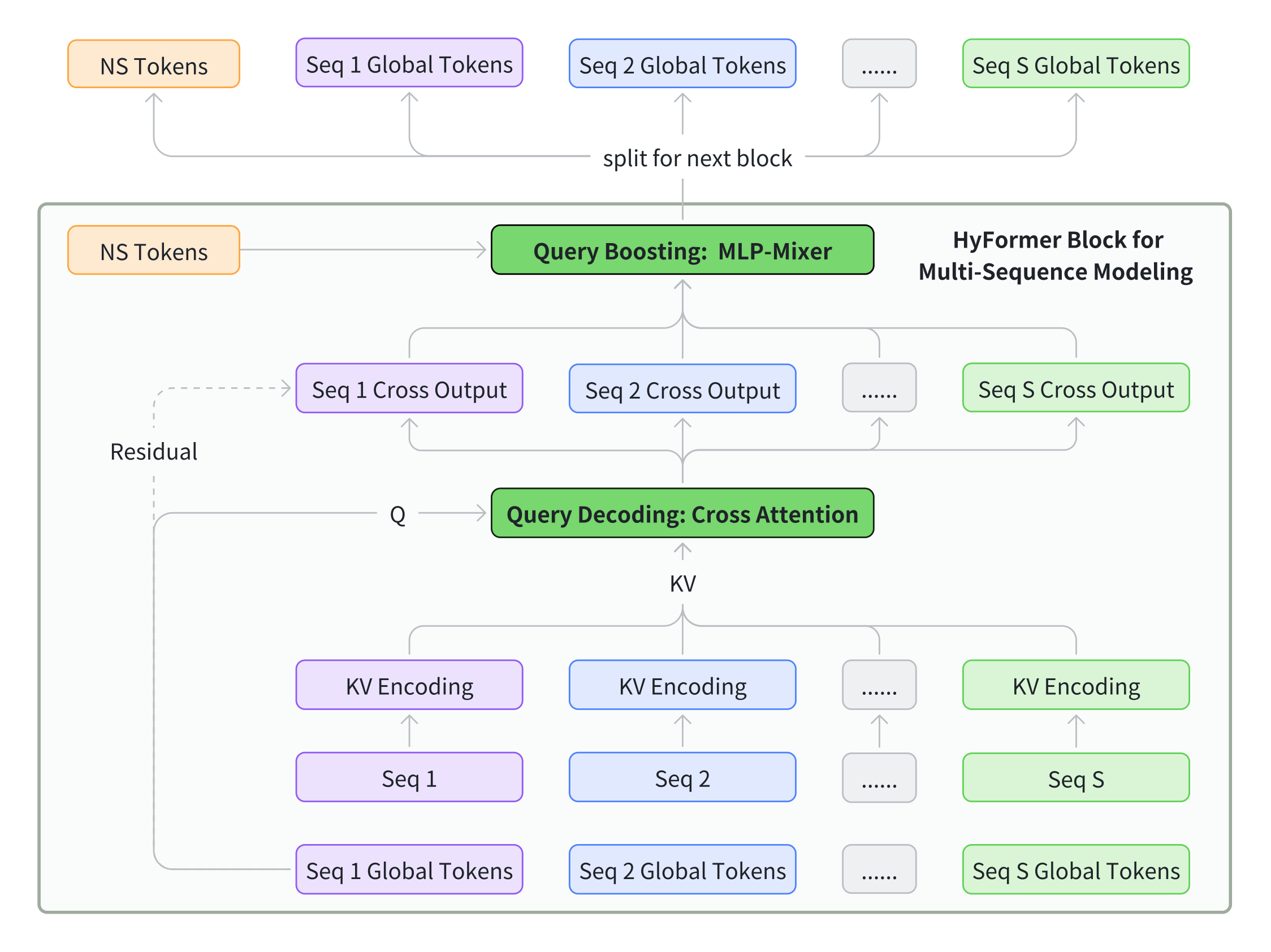
Figure 2. Multi-Sequence Modeling in HyFormer.
In industrial recommendation scenarios, user behaviors are often organized as multiple heterogeneous sequences, for example, video-watch sequence and product-purchase sequence. As practical multi-sequences are generally with different feature spaces and semantic representations, the authors empirically find that simple sequence merge adopted by MTGR [Han_2025] or OneTrans [zhang2025onetransunifiedfeatureinteraction] would lead to a significant degradation in performance. Thus, instead of merging different sequences into a single unified stream, HyFormer processes each behavior sequence independently in each HyFormer block for both efficiency and effectiveness. For each sequence, a dedicated set of query tokens is constructed and used to perform Query Decoding over the corresponding sequence representations. This design preserves sequence-specific semantics during decoding, while enabling cross-sequence interaction to be handled later through query-level token mixing, without requiring explicit sequence concatenation.
3.8 Training and Deployment Optimization¶
3.8.1 GPU Pooling for Long-Sequence¶
User long-sequence features can be extremely large, incurring significant data-transfer overhead and high memory pressure on the host. Fortunately, the number of truly unique feature IDs in such sequences is limited, typically around 25 percent of the total tokens. The method exploits this sparsity to deduplicate features, substantially reducing transfer costs and host-memory footprint. Specifically, before graph execution, features are stored in a compressed embedding table. During execution, a high-performance forward operator reconstructs the original sequence features directly on the GPU. In the backward pass, the companion backward operator aggregates gradients from the sequence features into gradients for the embedding table. These gradients are then propagated upstream to update the sparse parameters.
3.8.2 Asynchronous AllReduce¶
To mitigate idle time introduced by synchronous gradient aggregation, the system enables asynchronous AllReduce, allowing the gradient synchronization of step \(k\) to overlap with the forward and backward computation of step \(k+1\). This design effectively eliminates communication bubbles and maximizes GPU utilization. The trade-off is the introduction of one-step staleness for dense parameters: since their gradients are only available after the asynchronous reduction completes, the update rule becomes \(W_k = W_{k-1} + g_{k-1}\), indicating that dense parameters at step \(k\) use gradients from the previous step. In contrast, sparse parameters can be updated immediately after their local gradients are computed, yielding \(W_k = W_{k-1} + g_k\) and thus effectively staying one step ahead of the dense parameter updates. Although this hybrid update schedule introduces a small degree of temporal inconsistency between dense and sparse parameter states, empirical results indicate that this staleness does not degrade convergence quality or model performance in practice.
4. Experiments¶
Table 1. Overall Performance on Industrial Dataset¶
BaseArch: Traditional Two-Stage Models¶
| Sequence Modeling | Feature Interaction | AUC | Delta AUC | Params (x10^6) | FLOPs (x10^12) |
|---|---|---|---|---|---|
| LONGER [chai2025longerscalinglongsequence] | RankMixer [tolstikhin2021mlp; zhu2025rankmixerscalingrankingmodels] | 0.6478 | -- | 386 | 3.5 |
| LONGER [chai2025longerscalinglongsequence] | Full Transformer [vaswani2017attention] | 0.6472 | -0.09% | 416 | 6.2 |
| LONGER [chai2025longerscalinglongsequence] | Wukong [zhang2024wukong] | 0.6465 | -0.20% | 385 | 5.2 |
| Full Transformer [vaswani2017attention] | RankMixer [tolstikhin2021mlp; zhu2025rankmixerscalingrankingmodels] | 0.6481 | +0.05% | 388 | 6.6 |
| Full Transformer [vaswani2017attention] | Full Transformer [vaswani2017attention] | 0.6474 | -0.06% | 418 | 9.3 |
| Full Transformer [vaswani2017attention] | Wukong [zhang2024wukong] | 0.6468 | -0.15% | 387 | 8.3 |
UniArch: Unified-Block Models¶
| Model | AUC | Delta AUC | Params (x10^6) | FLOPs (x10^12) |
|---|---|---|---|---|
| MTGR/OneTrans (w/ LONGER) [Han_2025; zhang2025onetransunifiedfeatureinteraction] | 0.6480 | +0.03% | 406 | 6.6 |
| MTGR/OneTrans (w/ Full Transformer) [Han_2025; zhang2025onetransunifiedfeatureinteraction] | 0.6483 | +0.08% | 450 | 21.9 |
| HyFormer (Ours) | 0.6489 | +0.17% | 418 | 3.9 |
4.1 Experimental Setting¶
4.1.1 Datasets¶
The model is evaluated on the click-through-rate prediction task in the Douyin Search System, a real-world and large-scale industrial search recommendation scenario at ByteDance. The dataset is derived from a subset of online user interaction logs spanning 70 consecutive days and comprises 3 billion samples. Each sample incorporates user features, query features, document features, cross-features, and several sequential features. The three primary sequences used in the model are defined as follows:
- Long-term sequence: the user's long-term search and click behavior sequence, with an upper bound of 3000 in this study.
- Search sequence: the user's top-50 search behavior items, filtered by the Query Search module.
- Feed sequence: the user's top-50 feed behavior items, filtered by the Query Search module.
4.1.2 Baselines¶
The paper compares HyFormer against several strong baselines, which can be categorized into two architectural paradigms: Traditional Two-Stage Models and Unified-Architecture Models.
Traditional Two-Stage Models follow the prevalent mainstream design where sequence modeling and feature interaction are separated into two sequential stages. Sequential representations are first generated through a dedicated sequence modeling module and subsequently crossed with token-level representations of other features. For long-sequence modeling, the experiments use LONGER [chai2025longerscalinglongsequence] or Full Transformer [vaswani2017attention]. To capture interactions between tokenized features, the experiments employ RankMixer [zhu2025rankmixerscalingrankingmodels], Full Transformer [vaswani2017attention], and Wukong [zhang2024wukong].
Unified-Block Models adopt a joint modeling approach where both sequential and non-sequential features are tokenized and processed simultaneously within a single model block. This integrates sequence modeling and heterogeneous feature interaction into one unified stage. An example is MTGR [Han_2025], which tokenizes all features and models them jointly using a transformer-style backbone. Similarly, OneTrans [zhang2025onetransunifiedfeatureinteraction] follows a comparable simplified design, as it adopts a pyramid-compressed structure as backbone. In the authors' implementation of the MTGR/OneTrans models, MTGR/OneTrans (LONGER) performs only cross-attention between non-sequential and sequential features, without inner-sequence self-attention. MTGR/OneTrans (Full Transformer) uses full self-attention in sequence to achieve better performance with increased FLOPs.
4.1.3 Evaluation Metrics¶
For offline evaluation, the paper uses Query-level AUC, which calculates the AUC [hand2001simple] for samples within each query and then averages the results across all queries. It also reports the number of dense parameters and training FLOPs, with FLOPs computed using a batch size of 2048.
4.1.4 Implementation Details¶
For the convenience of experimentation, the recommendation model is cold-started for offline evaluation and warmed up with checkpoints for online evaluation. All baselines use the same batch size of 2048 and the same optimizer settings. The input token count for all MLP-Mixer modules is aligned to 16. In the multi-sequence HyFormer implementation, it comprises 13 non-sequential tokens and 3 global tokens, one per sequence, summing to a total of 16 tokens. All models are trained with the same hyperparameter tuning, and experiments are conducted on a 64-GPU cluster.
4.2 Overall Performance¶
4.2.1 Comparison of Existing Methods¶
The proposed HyFormer architecture achieves the highest AUC among all evaluated models, outperforming both traditional two-stage models (BaseArch) and other unified-block models (UniArch). Within the BaseArch group, performance varies significantly with component choice: for feature interaction, RankMixer [zhu2025rankmixerscalingrankingmodels] consistently outperforms Self-Attention and Wukong [zhang2024wukong], while for sequence modeling, incorporating full self-attention within the sequence generally yields gains. Notably, the best-performing BaseArch combination that employs a Full Transformer for sequence modeling with RankMixer still falls short of HyFormer, owing to its inherent limitation of unidirectional information flow. Furthermore, HyFormer demonstrates superior computational efficiency. Despite achieving the highest accuracy, it requires only \(3.9 \times 10^{12}\) total FLOPs during training, which is significantly lower than that of most competitors, including other high-performing models such as MTGR [Han_2025].
Unified architectures like HyFormer and MTGR demonstrate that integrating sequence modeling and feature interaction into a cohesive design enhances overall effectiveness. However, as evidenced by the results, MTGR/OneTrans [Han_2025; zhang2025onetransunifiedfeatureinteraction] relies on Self-Attention for feature interaction, an approach that often degrades AUC and significantly compromises computational efficiency in the interaction module [zhu2025rankmixerscalingrankingmodels]. HyFormer therefore distinguishes itself by achieving the best accuracy without resorting to such costly substitutions or complex modeling on the sequence key-value side. This validates its core design principle of iterative query decoding and boosting within a unified block. Besides, MTGR/OneTrans combines Global Tokens and Seq Tokens as keys, while exclusively using Global Tokens as queries. This design facilitates Global Tokens attending more readily to themselves rather than to sequence tokens. In contrast, HyFormer enforces a separated information flow: it first compresses and absorbs concrete sequence item information into Global Tokens, and then conducts interaction between different abstract Global Tokens, with this two-step process repeatedly stacked across layers. Furthermore, the hybrid architecture of HyFormer offers greater flexibility for future scaling. It allows independent adjustment of interaction layers and dimensions and sequence modeling layers and dimensions, providing a more adaptable framework than methods that rigidly bind feature interaction and sequence modeling within a single standard attention layer.
4.2.2 Ablation Study¶
Table 2 presents an ablation study on the primary contributors to HyFormer's performance improvement.
Ablation of Query Global Context¶
| Configuration | AUC | Delta AUC | Params (x10^6) | FLOPs (x10^12) |
|---|---|---|---|---|
| HyFormer | 0.6489 | -- | 418 | 3.9 |
| Query w/o Seq Pooling Tokens | 0.6486 | -0.05% | 415 | 3.9 |
| Query w/o Nonseq and Seq Pooling Tokens | 0.6484 | -0.08% | 414 | 3.8 |
Ablation of Query Boosting¶
| Configuration | AUC | Delta AUC | Params (x10^6) | FLOPs (x10^12) |
|---|---|---|---|---|
| HyFormer | 0.6489 | -- | 418 | 3.9 |
| HyFormer w/o Global Tokens | 0.6484 | -0.08% | 414 | 3.8 |
| BaseArch w/ Global Tokens | 0.6480 | -0.14% | 505 | 3.6 |
| BaseArch w/o Global Tokens | 0.6478 | -0.17% | 387 | 3.5 |
Ablation of Multi-Sequence Modeling¶
| Configuration | AUC | Delta AUC | Params (x10^6) | FLOPs (x10^12) |
|---|---|---|---|---|
| HyFormer | 0.6489 | -- | 418 | 3.9 |
| HyFormer + Merge Seq | 0.6485 | -0.06% | 397 | 3.9 |
First, the paper ablates the components of the query. The HyFormer query is generated from three sources: global non-sequential features, multiple sequence pooling tokens, and the original target features. Experiments show that reverting the query to its original target-feature-only state severely limits subsequent deep feature interaction, causing a 0.08 percent AUC decline. Removing the cross-sequence pooling tokens from the full query also leads to a 0.05 percent AUC loss, confirming that inter-sequence interaction contributes meaningfully within the HyFormer structure.
Second, the paper evaluates the overall architectural change. Restoring the baseline architecture, LONGER plus RankMixer, which applies sequential modeling followed by separate feature interaction, shows that even with enriched query information, the lack of deepened interaction caps the gains, yielding only a 0.03 percent AUC improvement. In contrast, within the HyFormer framework, which is designed to strengthen interaction throughout the model, expanding query information delivers a significantly larger 0.08 percent AUC gain.
Third, the paper conducts an ablation study on the multi-sequence modeling strategy within HyFormer. Two principal paradigms exist for handling multiple sequences: merging sequences into one via dimension alignment and concatenation for joint modeling, or keeping sequences separate and modeling them independently. HyFormer adopts the latter approach, using distinct query tokens for each sequence. In the experiments, sequence merging and query sharing resulted in a significant AUC loss of 0.06 percent. This highlights the advantages of HyFormer in expanding queries and enabling broader feature interaction. Additionally, merging forces disparate sequences to share global tokens, ignoring their distinctiveness. The resulting representations capture far less differentiated information than HyFormer's separate modeling of each sequence. The authors speculate that this inherent limitation of sequence merging also partly explains why models like MTGR and OneTrans underperform compared to HyFormer.
In summary, the HyFormer architecture provides a versatile multi-sequence modeling framework by employing independent tokens for different sequences, thereby eliminating the need for forced alignment of side information or sparse dimensions across sequences. This design not only preserves the inherent distinctions between sequences to a great extent, but also enables the adaptive allocation of more global tokens to more important sequences, which yielded measurable gains in the offline experiments.
4.3 Scaling Analysis¶
This section presents the scaling analysis of model performance with respect to sequence side information, FLOPs, and the number of parameters. As shown in the overall performance table, under the paradigm of first performing sequential modeling and then performing heterogeneous feature interaction, LONGER plus RankMixer achieves the best performance and is currently the production baseline. Therefore, the paper uses it as the control group in the scaling experiments to compare the scaling performance of the HyFormer architecture.
4.3.1 Parameters and FLOPs¶
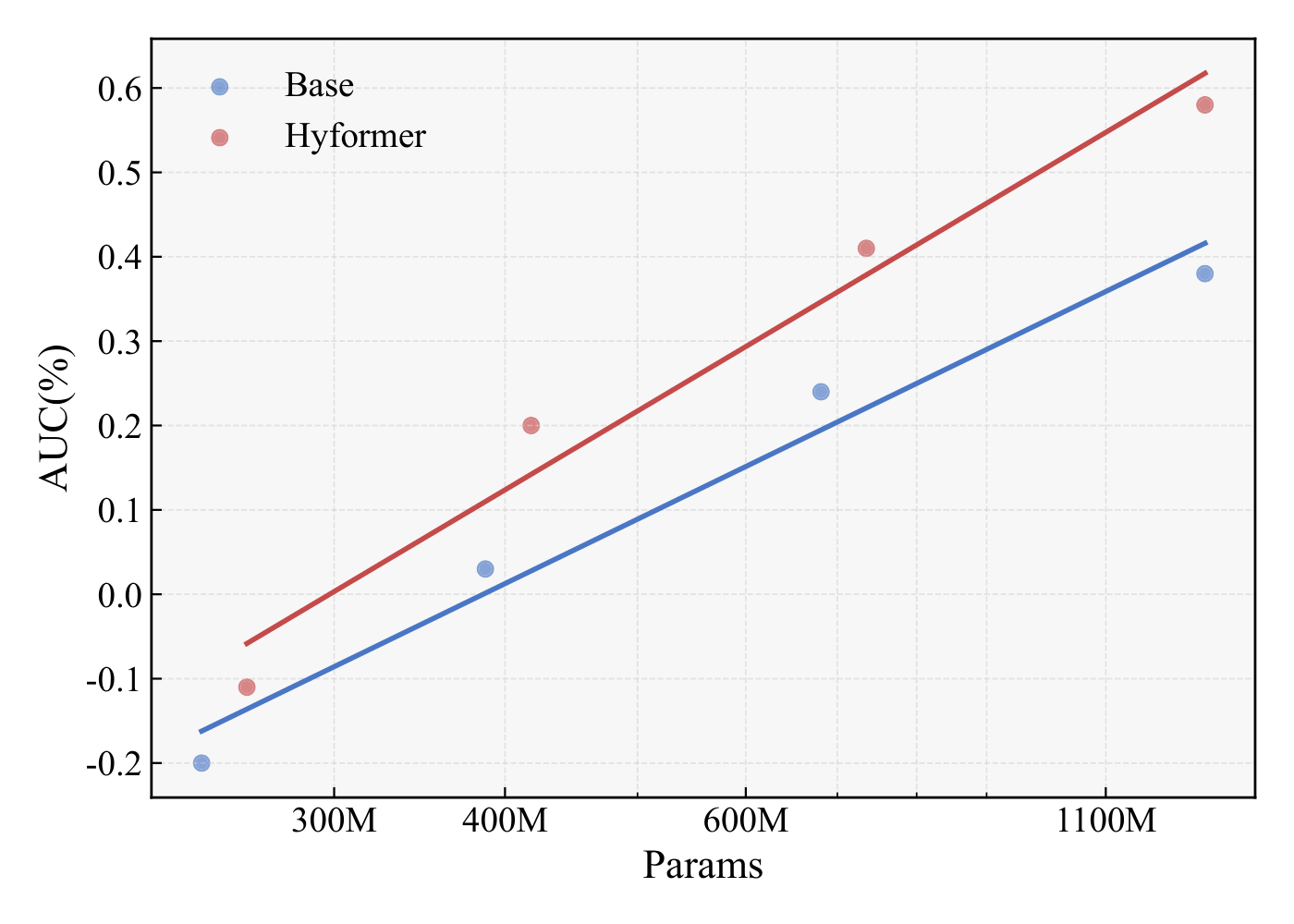
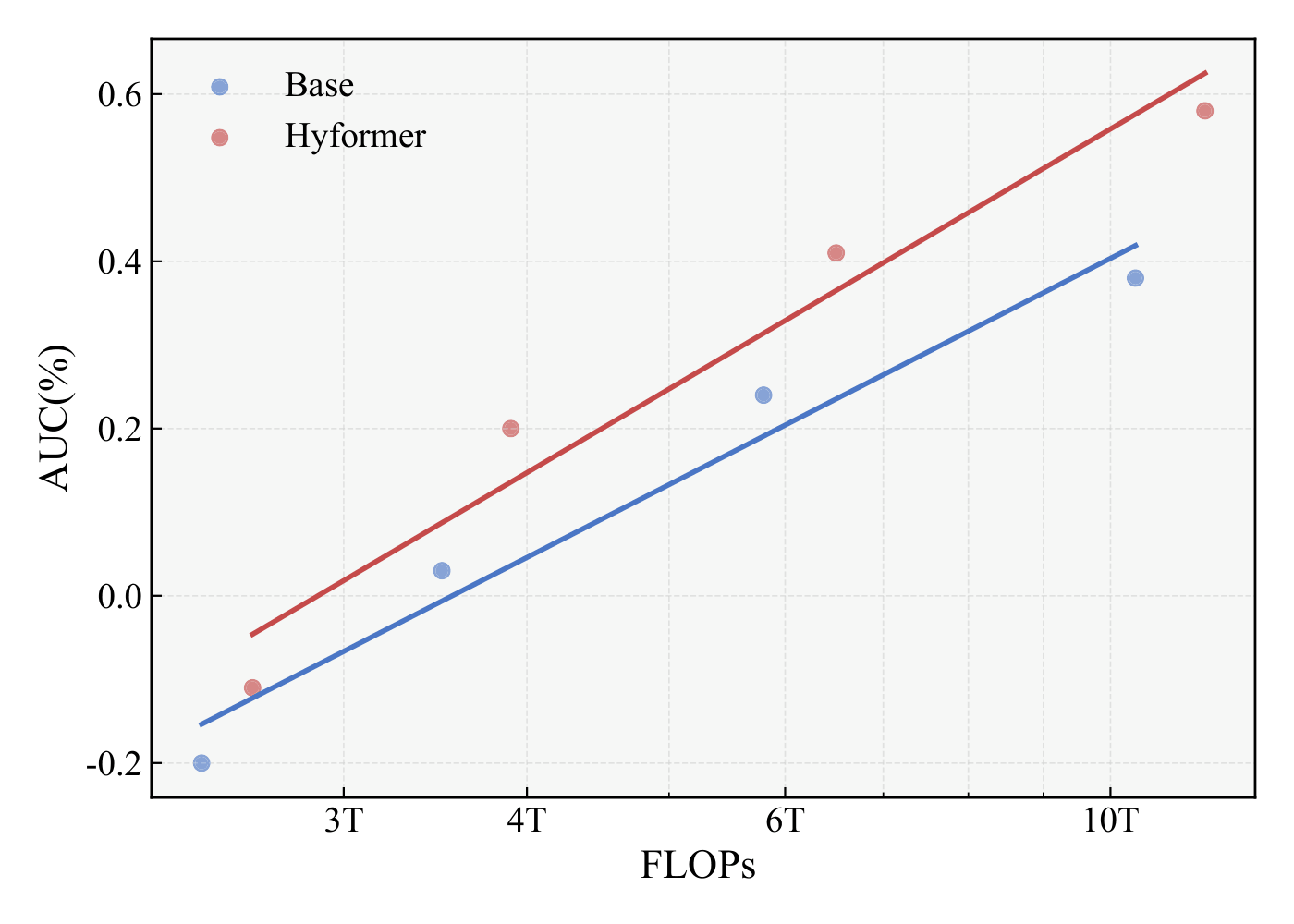
Figure 3. Scaling performance with respect to FLOPs and model parameters.
The paper examines the scaling law of the HyFormer architecture across model sizes ranging from 200M to 1B+ parameters. While HyFormer initially outperforms the baseline LONGER plus RankMixer model, it maintains strong scaling benefits overall, exhibiting a steeper slope than the baseline. This indicates that the bidirectional information flow, enabled by the alternating stacked layers of LONGER and RankMixer in HyFormer, allows it to achieve significantly greater gains from increasing depth compared to the baseline at similar parameter scales.
A similar pattern emerges when scaling law is analyzed in terms of computational cost. AUC increases steadily with FLOPs, following a strong power-law trend. This indicates that increasing computational resources enables the model to process sequences with richer information, benefiting from the expansion of the initial query and the repeated enhancement of the query through feature interaction in MLP-Mixer, ultimately leading to greater AUC improvement.
These results suggest that the architectural design of HyFormer prioritizes scaling efficiency, yielding greater gains per parameter via enriched heterogeneous feature interactions, which results in a steeper performance scaling curve.
4.3.2 Sparse Dimension¶
Table 3. Scaling with Sequence Sparse Dimension¶
| Seq Length | Arch | Seq Sparse Dim | AUC | Delta AUC | Delta AUC Gap |
|---|---|---|---|---|---|
| 1k | BaseArch | 64 | 0.6478 | -- | -- |
| 1k | BaseArch | 224 | 0.6484 | +0.09% | -- |
| 1k | HyFormer | 64 | 0.6489 | -- | -- |
| 1k | HyFormer | 224 | 0.6497 | +0.12% | +0.03% |
| 3k | BaseArch | 64 | 0.6486 | -- | -- |
| 3k | BaseArch | 224 | 0.6490 | +0.06% | -- |
| 3k | HyFormer | 64 | 0.6499 | -- | -- |
| 3k | HyFormer | 224 | 0.6507 | +0.12% | +0.06% |
The paper also analyzes how model performance varies with the expansion of the sequence token input dimension, that is, the richness of sequence side information. Regardless of sequence length, enriching sequence side information consistently brings greater benefits to the HyFormer framework than to the baseline LONGER plus RankMixer framework. For sequences of length 1000, expanding the sparse dimension width from the original 64 dimensions with three side information types to 224 dimensions with seven types yielded a Delta AUC of 0.09 percent for the baseline, compared to a 0.12 percent gain for HyFormer. The improvement for HyFormer is significantly larger, a trend that holds across other sequence lengths in experiments. Furthermore, the performance gap between HyFormer and the BaseArch widens as sequences grow longer, with the additional gain from dimension expansion increasing from 0.03 percent at 1k sequence length to 0.06 percent at 3k.
These results indicate that expanding the sequence key/value information delivers greater value within the HyFormer framework, and this advantage becomes more pronounced with longer sequences. The benefit stems from HyFormer's ability to integrate richer global information into sequence queries, coupled with the bidirectional information flow between its LONGER and Mixer modules, which collectively enable more thorough feature interaction.
4.4 Online A/B Tests¶
This section presents the online A/B test results for the HyFormer model on the Douyin Search platform, where it was evaluated against a strong existing RankMixer baseline. For online evaluation, the paper uses three key metrics: Average Watch Time Per User, Video Finish Play Count Per User, and Query Change Rate. In particular, the Query Change Rate quantifies the probability of a user manually refining a search query to a more specific one, for example from "iPhone" to "iPhone 17 Pro", which is calculated as follows:
where \(N_{\mathrm{reform}}\) is the number of distinct user-query pairs with query reformulation, and \(N_{\mathrm{total}}\) is the total number of distinct user-query pairs. This metric serves as an indicator of a negative search experience for users.
As shown in the online A/B test results, the test confirms substantial improvements across key metrics: a 0.293 percent increase in average watch time per user, a 1.111 percent growth in video finish play count per user, and a 0.236 percent decrease in query change rate. These significant gains demonstrate the practical value and effectiveness of HyFormer in a real-world, billion-user platform environment.
Table 4. Online A/B Test Results on Douyin¶
| Online Test Metric | Gain |
|---|---|
| Average Watch Time Per User (up) | +0.293% |
| Video Finish Play Count Per User (up) | +1.111% |
| Query Change Rate (down) | -0.236% |
5. Conclusions¶
In this paper, the authors propose the HyFormer architecture. In contrast to the prevalent "Long Sequence Modeling, Then Feature Interaction" paradigm which first performs sequential modeling and then conducts heterogeneous feature interaction in a unidirectional flow, HyFormer introduces Global Tokens to redefine the roles of long-sequence modeling and feature interaction by boosting the query capacity via feature interaction. The architecture alternates between two core components: Query Decoding and Query Boosting. From a sequential modeling perspective, this corresponds to an iterative optimization process that alternates between decoding long sequences using the Global Tokens and enhancing the Global Tokens through cross-feature interaction. This design provides a novel and effective framework for more thorough sequence modeling and feature interaction, while also providing a flexible paradigm for multi-sequence modeling. Extensive offline and online experiments validate the superiority of upgrading from a unidirectional information flow to a bidirectional, co-evolutionary paradigm, and also raise the scaling ceiling for future LRMs in industry.
References¶
- Xu_2025. Songpei Xu, Shijia Wang, Da Guo, Xianwen Guo, Qiang Xiao, Bin Huang, Guanlin Wu, and Chuanjiang Luo. Climber: Toward Efficient Scaling Laws for Large Recommendation Models. CIKM 2025.
- Zivic_2024. Pablo Zivic, Hernan Vazquez, and Jorge Sanchez. Scaling Sequential Recommendation Models with Transformers. SIGIR 2024.
- borisyuk2024lirank. Fedor Borisyuk et al. LiRank: Industrial Large Scale Ranking Models at LinkedIn. KDD 2024.
- gui2023hiformer. Huan Gui et al. Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems. arXiv 2023.
- yu2025hhfthierarchicalheterogeneousfeature. Liren Yu et al. HHFT: Hierarchical Heterogeneous Feature Transformer for Recommendation Systems. arXiv 2025.
- xu2025store. Yi Xu et al. STORE: Semantic Tokenization, Orthogonal Rotation and Efficient Attention for Scaling Up Ranking Models. arXiv 2025.
- khrylchenko2025scaling. Kirill Khrylchenko et al. Scaling Recommender Transformers to One Billion Parameters. arXiv 2025.
- zhou2018deep. Guorui Zhou et al. Deep Interest Network for Click-Through Rate Prediction. KDD 2018.
- zhou2019deep. Guorui Zhou et al. Deep Interest Evolution Network for Click-Through Rate Prediction. AAAI 2019.
- feng2019deep. Yufei Feng et al. Deep Session Interest Network for Click-Through Rate Prediction. arXiv 2019.
- zhai2024actions and zhai2024actionsspeaklouderwords. Jiaqi Zhai et al. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. arXiv 2024.
- chai2025longerscalinglongsequence. Zheng Chai et al. LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders. arXiv 2025.
- qi2020searchbasedusermodelinglifelong. Pi Qi et al. Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction. arXiv 2020.
- chen2022efficient. Qiwei Chen et al. Efficient Long Sequential User Data Modeling for Click-Through Rate Prediction. arXiv 2022.
- chang2023twintwostagenetworklifelong. Jianxin Chang et al. TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou. arXiv 2023.
- Si_2024. Zihua Si et al. TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou. CIKM 2024.
- Xia_2023. Xue Xia et al. TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest. KDD 2023.
- guo2017deepfmfactorizationmachinebasedneural. Huifeng Guo et al. DeepFM: A Factorization-Machine Based Neural Network for CTR Prediction. arXiv 2017.
- Lian_2018. Jianxun Lian et al. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems. KDD 2018.
- Wang_2021. Ruoxi Wang et al. DCN V2: Improved Deep and Cross Network and Practical Lessons for Web-scale Learning to Rank Systems. WWW 2021.
- zhang2024wukong. Buyun Zhang et al. Wukong: Towards a Scaling Law for Large-Scale Recommendation. arXiv 2024.
- zhu2025rankmixerscalingrankingmodels. Jie Zhu et al. RankMixer: Scaling Up Ranking Models in Industrial Recommenders. arXiv 2025.
- Han_2025. Ruidong Han et al. MTGR: Industrial-Scale Generative Recommendation Framework in Meituan. CIKM 2025.
- zeng2025interformereffectiveheterogeneousinteraction. Zhichen Zeng et al. InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction. arXiv 2025.
- zhang2025onetransunifiedfeatureinteraction. Zhaoqi Zhang et al. OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender. arXiv 2025.
- vaswani2017attention. Ashish Vaswani et al. Attention Is All You Need. NeurIPS 2017.
- tolstikhin2021mlp. Ilya O. Tolstikhin et al. MLP-Mixer: An All-MLP Architecture for Vision. NeurIPS 2021.
- hand2001simple. David J. Hand and Robert J. Till. A Simple Generalisation of the Area under the ROC Curve for Multiple Class Classification Problems. Machine Learning, 2001.