InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction¶
Converted from the LaTeX source under arXiv-2411.09852v4.
Converted figures now live under img/interformer/ and are referenced directly from this markdown file.
Authors¶
Zhichen Zeng, Xiaolong Liu, Mengyue Hang, Xiaoyi Liu, Qinghai Zhou, Chaofei Yang, Yiqun Liu, Yichen Ruan, Laming Chen, Yuxin Chen, Yujia Hao, Jiaqi Xu, Jade Nie, Xi Liu, Buyun Zhang, Wei Wen, Siyang Yuan, Hang Yin, Xin Zhang, Kai Wang, Wen-Yen Chen, Yiping Han, Huayu Li, Chunzhi Yang, Bo Long, Philip S. Yu, Hanghang Tong, and Jiyan Yang.
Notes:
- The original paper marks Zhichen Zeng, Xiaolong Liu, Mengyue Hang, and Xiaoyi Liu as equal contributors.
Affiliations:
- University of Illinois Urbana-Champaign
- Meta AI
- University of Illinois Chicago
Abstract¶
Click-through rate (CTR) prediction estimates the probability that a user will click an ad or item, and it remains a core problem in recommender systems. Modern CTR pipelines must combine heterogeneous information, especially static non-sequential features such as user profile and context together with dynamic behavior sequences. Existing methods still suffer from two recurring problems: insufficient inter-mode interaction caused by mostly one-way information flow, and aggressive information aggregation caused by early summarization that discards useful detail. InterFormer addresses both issues by learning heterogeneous interaction in an interleaving style. It enables bidirectional information flow so non-sequential and sequential representations can improve one another, while a separate Cross Arch performs selective information exchange instead of collapsing representations too early. The model has been deployed across multiple Meta Ads platforms, where it reports a 0.15% performance gain and a 24% QPS gain over prior state-of-the-art systems.
Keywords¶
- Recommendation
- CTR Prediction
- Heterogeneous Information
1. Introduction¶
Click-through rate prediction is a fundamental task in online advertising and recommender systems [zhang2022dhen; zhang2024wukong]. The quality of CTR prediction directly affects both business revenue and user experience, so it has received sustained attention from both academia and industry [zhou2018deep; zhou2019deep; liu2024collaborative; liang2025external; yoo2024ensuring; liu2023class; liu2024aim; liu2025breaking]. In ad bidding, CTR models help advertisers set better bids and reach more relevant audiences. In content recommendation, they determine which content is surfaced to which users.
Accurate CTR prediction depends on understanding user interests in a changing environment [zhou2018deep; lyu2020deep; wang2019sequential]. Heterogeneous information creates both opportunity and difficulty. Non-sequential features such as user profile and context provide a relatively static view of general user preference, while behavior sequences reveal dynamic and often short-term interests [zhang2017joint; wang2019sequential]. Because these data modes behave differently, they usually require different modeling strategies and careful integration [zhang2017joint]. Feature interaction is central for non-sequential information [rendle2010factorization; lian2018xdeepfm; wang2021dcn], whereas sequence modeling is central for user behavior history [sun2019bert4rec; chen2019behavior].
Most existing CTR models still fall into two broad categories: non-sequential models and sequential models. Non-sequential models focus on feature interaction using inner products [lian2018xdeepfm; sun2021fm2], MLP-based architectures [wang2017deep; wang2021dcn], or deep structured semantic models [huang2013learning; elkahky2015multi], but they ignore user behavior sequences. Sequential models add dedicated components such as CNNs [tang2018personalized], RNNs [sun2019bert4rec; zhou2018deep], or attention mechanisms [lyu2020deep; zhou2019deep; zhai2024actions] to capture dependencies in user behavior. Even so, most sequential methods still rely on a mostly unidirectional information flow: non-sequential context guides sequence learning, but sequence information rarely feeds back into non-sequence representation learning. That restriction leads to insufficient interaction between data modes. For example, non-sequential features may encode long-term interests, while the recent sequence may reveal a sudden short-term preference that should refine the non-sequential context.
Another weakness is aggressive information aggregation. Because direct interaction among many non-sequence features and long sequences is expensive, many systems summarize sequences early through summation [zhou2018deep], pooling [xiao2020deep], or concatenation [zhou2019deep]. That early compression is efficient, but it also causes irreversible information loss.
InterFormer is proposed to address both issues. The design follows two principles:
- Avoid insufficient inter-mode interaction by enabling bidirectional information flow, so non-sequence and sequence learning proceed in an interleaving manner.
- Avoid aggressive information aggregation by retaining full representations in each mode and using a dedicated Cross Arch for selective information exchange and summarization.
More concretely, InterFormer uses non-sequence summarization to guide sequence modeling through Personalized FeedForward Network (PFFN) and Multi-Head Attention (MHA) [vaswani2017attention]. It also uses sequence summarization to guide non-sequence learning through an interaction module. The framework is compatible with multiple interaction backbones, including DCNv2 [wang2021dcn] and DHEN [zhang2022dhen].
The main contributions are as follows:
- Challenges. The paper identifies two key bottlenecks in heterogeneous interaction learning: insufficient inter-mode interaction and aggressive information aggregation.
- Model design. It introduces InterFormer, a heterogeneous interaction framework that supports effective feature interaction and selective information aggregation. The central idea is mutual benefit between non-sequential and sequential representations.
- Experiments and analysis. InterFormer reports up to 0.14% AUC improvement on benchmark datasets and 0.15% Normalized Entropy gain on an industrial dataset. Internal Meta deployment also shows promising scaling properties, a 0.15% performance gain, and a 24% QPS gain over strong CTR baselines.
2. Related Works¶
Recommender systems have received extensive attention in the broader big-data and AI era [yan2021dynamic; yan2021bright; yan2023trainable; yan2023reconciling; yan2022dissecting; yan2024pacer; yan2024topological; yan2024thegcn; yanred; xu2024slog; yu2025joint; yu2025planetalign; zeng2024graph; zeng2025pave; zeng2023parrot; zeng2023generative; zeng2024hierarchical; bao2024matcha; xu2024discrete; lin2024duquant; lin2025quantization; lin2025toklip]. This section groups prior work into non-sequential and sequential CTR methods.
2.1 Non-Sequential Methods¶
Most non-sequential CTR models are built on top of Factorization Machines (FM) [rendle2010factorization; lian2018xdeepfm; sun2021fm2], which model user-item interaction through low-dimensional embeddings [zhang2019deep]. The original FM model captures pairwise interactions [rendle2010factorization]. To model higher-order interactions, later work combines FMs with deep networks, where the FM component handles low-order interaction and the neural network captures higher-order patterns. Typical examples include MLP-based architectures [lian2018xdeepfm; yang2017bridging; wang2021dcn; sun2021fm2; zhou2020can] and attention-based approaches [song2019autoint; xiao2017attentional; xin2019cfm]. These models support end-to-end training and can accommodate heterogeneous signals such as text, image, and video [zhang2019deep]. Recent large-scale work also studies scaling behavior. DHEN [zhang2022dhen] ensembles multiple interaction modules, and Wukong [zhang2024wukong] stacks FM-style modules into a hierarchy. Even so, non-sequential models do not directly model sequential dependencies, which limits performance whenever user behavior history matters.
2.2 Sequential Methods¶
Sequential recommendation methods aim to capture evolving user interests from interaction histories. A core challenge is how to combine sequential and non-sequential information in a mutually beneficial way. Earlier methods used Markov-style assumptions [shani2005mdp; he2016fusing; yang2020hybrid], but those assumptions are often too restrictive for long-term dependency modeling [quadrana2018sequence]. More recent approaches use RNNs and attention. Various attention-based architectures [zhou2019deep; lyu2020deep] and Transformer-style models [devlin2018bert; vaswani2017attention; lin2025cats; sun2019bert4rec; chen2019behavior] have been proposed for sequential recommendation. Some methods also model multiple user interests or multiple behavior sequences [xiao2020deep; han2024efficient]. Industrial ranking systems such as TransAct [xia2023transact], LiRank [borisyuk2024lirank], and CARL [chen2024cache] push this direction further.
The paper argues that most existing sequential methods still mainly use non-sequential information to personalize sequence modeling, while the reverse direction is underexplored. That one-way design reduces the expressiveness of the learned representations and motivates a bidirectional framework such as InterFormer.
3. Preliminaries¶
This section introduces the notation and background modules used by the paper.
3.1 Symbols and Notation¶
The paper uses bold uppercase letters for matrices such as \(\mathbf{X}\), bold lowercase letters for vectors such as \(\mathbf{x}\), and lowercase letters for scalars such as \(n\). The element at row \(i\) and column \(j\) of a matrix \(\mathbf{X}\) is written as \(\mathbf{X}(i, j)\), and the transpose is written as \(\mathbf{X}^{\mathsf{T}}\). Superscript \(u\) denotes users. Subscripts \(i\) and \(t\) denote items and timestamps. The notation \(\mathbf{x}_j^{(l)}\) refers to the \(j\)-th non-sequence feature at layer \(l\), and \(\mathbf{s}_t^{(l)}\) refers to the sequence feature at layer \(l\) and time step \(t\).
| Symbol | Definition |
|---|---|
| \(\mathcal{U}, \mathcal{I}\) | user set and item set |
| \(\mathbf{x}_j^{(l)}\) | \(j\)-th non-sequence feature of layer \(l\) |
| \(\mathbf{s}_t^{(l)}\) | sequence feature of layer \(l\) at time step \(t\) |
| \(m, n, k\) | number of dense, sparse, and sequence features |
| \(T, d\) | sequence length and embedding dimension |
| \(\odot\) | Hadamard product |
| \(\langle \cdot, \cdot \rangle\) | inner product |
| \(\[\cdot \Vert \cdot\]\) | horizontal concatenation of vectors |
3.2 Click-Through Rate Prediction¶
CTR prediction estimates the probability that a user clicks an item given heterogeneous information such as static context and behavior sequences. Let \(\mathcal{U}\) be the user set and \(\mathcal{I}\) the item set. For a user \(u \in \mathcal{U}\), define the interaction sequence as:
where each \(i_t^u \in \mathcal{I}\) is the interacted item at time step \(t\). The goal is to estimate the click probability for a new item \(i_{T+1}^u\):
The model is typically optimized with cross-entropy loss. Because the formulation explicitly includes temporal behavior through \(S^u\), it can capture sequential patterns that non-sequential methods miss.
3.3 Feature Interaction¶
Feature interaction is central to CTR modeling. The paper reviews three representative modules: inner product interaction, DCNv2, and DHEN.
3.3.1 Inner Product-Based Interaction¶
Given an input vector \(\mathbf{x} \in \mathbb{R}^d\), Factorization Machines learn a latent vector \(\mathbf{v}_j \in \mathbb{R}^r\) for each feature \(j\). The second-order interaction function is:
3.3.2 Deep and Cross Network v2¶
DCNv2 combines explicit cross layers with a deep neural component. Given input \(\mathbf{x}^{(0)} \in \mathbb{R}^d\), the cross layer at depth \(l\) is:
The stacked cross layers model explicit feature interactions, while the parallel deep branch models implicit interactions.
3.3.3 Deep Hierarchical Ensemble Network¶
DHEN builds a hierarchy of feature interactions by combining several interaction modules within each layer. Given concatenated features \(\mathbf{X}^{(l)} \in \mathbb{R}^{d \times m}\), the next layer is:
This layered ensemble lets DHEN combine the strengths of multiple interaction mechanisms.
3.4 Attention Mechanism¶
Attention is a core tool for sequence modeling [bahdanau2014neural; vaswani2017attention; devlin2018bert]. The paper highlights Multi-Head Attention and Pooling by Multi-Head Attention.
3.4.1 Multi-Head Attention¶
Given a sequence \(\mathbf{S} = \[\mathbf{s}_1, \dots, \mathbf{s}_T\]\), self-attention is defined as:
where \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\) are projected queries, keys, and values. Multi-Head Attention then aggregates \(h\) parallel heads:
with
3.4.2 Pooling by Multi-Head Attention¶
PMA replaces the input-derived query with a learnable query matrix \(\mathbf{Q}_{\mathrm{PMA}} \in \mathbb{R}^{k \times d_k}\), which summarizes a sequence from \(k\) learned perspectives:
Each learnable query acts as a seed vector that extracts one summarization of the sequence.
4. Methodology¶
InterFormer contains three major components: Interaction Arch, Sequence Arch, and Cross Arch. The Interaction Arch learns behavior-aware non-sequence embeddings. The Sequence Arch learns context-aware sequence embeddings. The Cross Arch summarizes and exchanges information between the two modes.
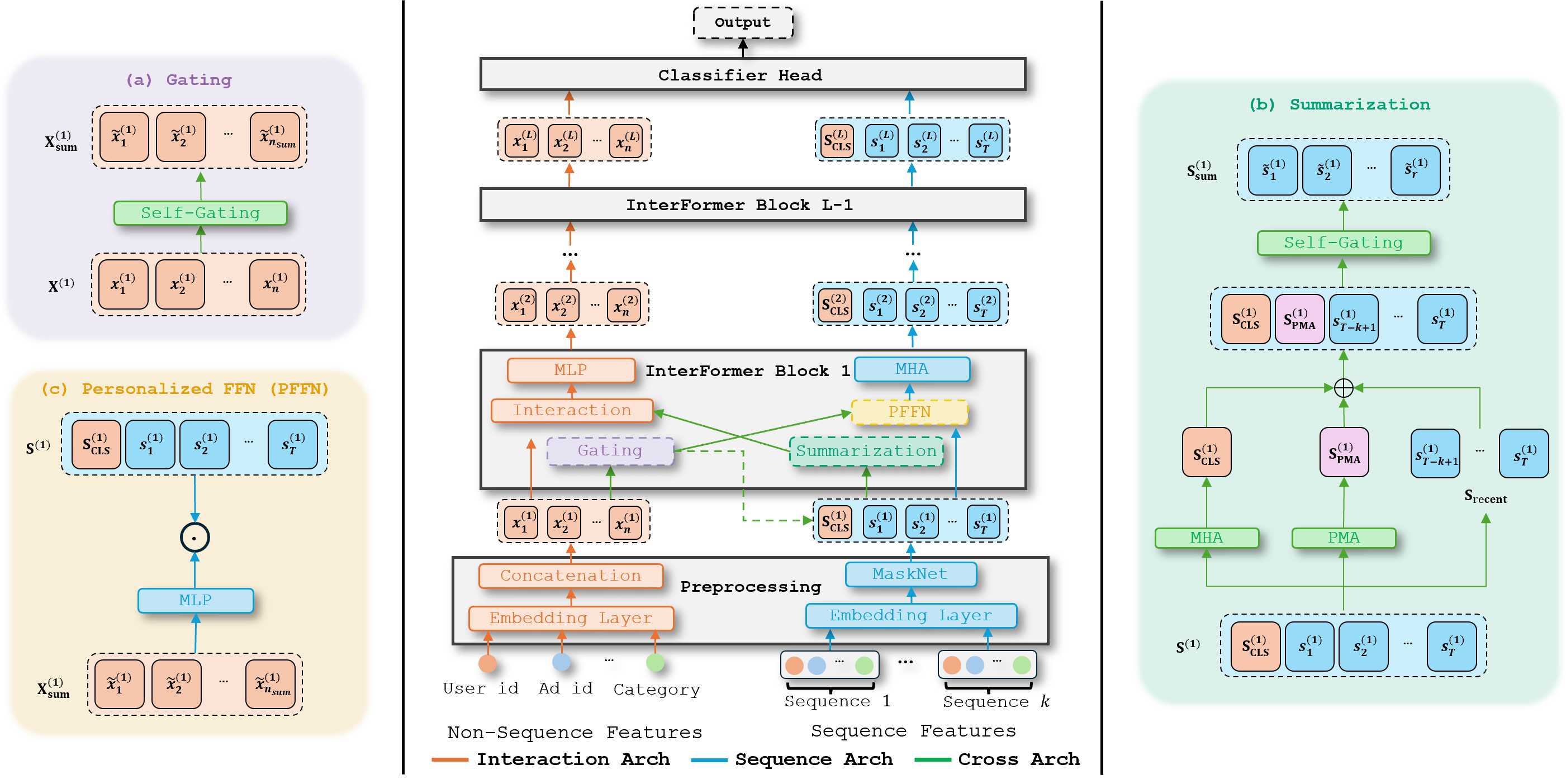
Figure 1. Overview of the InterFormer architecture. Each block contains an Interaction Arch, a Sequence Arch, and a Cross Arch. The dashed line for CLS token appending appears only in the first layer.
4.1 Feature Preprocessing¶
4.1.1 Non-Sequence Feature Preprocessing¶
The model handles two types of non-sequence features: dense features such as user age and item price, and sparse features such as user ID and item category. All feature types are projected into the same embedding dimension.
Dense features are concatenated into
and then mapped to a dense embedding:
Each sparse feature is encoded as a one-hot vector and projected into the same \(d\)-dimensional space. Concatenating dense and sparse embeddings yields the non-sequence feature matrix:
4.1.2 Sequence Feature Preprocessing¶
Each item in the behavior sequence is embedded into \(\mathbb{R}^d\), producing:
In real systems, users may have multiple behavior sequences from different actions or platforms. These sequences are often noisy. To unify them and suppress irrelevant information, the paper uses MaskNet [wang2021masknet]. Given \(k\) sequences \(\mathbf{S}_1, \dots, \mathbf{S}_k\), the combined representation is:
where \(\mathrm{MLP}_{\mathrm{mask}}\) learns a self-mask and \(\mathrm{MLP}_{\mathrm{lce}}\) compresses the multiple sequences back to dimension \(d \times T\).
4.2 Interaction Arch: Behavior-Aware Interaction Learning¶
Non-sequence features encode static user preference, while behavior sequences provide dynamic preference information [lian2018xdeepfm; zhang2022dhen; zhou2019deep]. InterFormer uses sequence summarization to improve non-sequence feature interaction learning. Given non-sequence input \(\mathbf{X}^{(l)}\) and sequence summary \(\mathbf{S}_{\mathrm{sum}}^{(l)}\) at layer \(l\), the Interaction Arch produces:
The interaction backbone is not fixed. Inner product, DCNv2, DHEN, and similar models can all serve as the Interaction Arch. Appending sequence summary allows the model to capture both explicit non-sequence interactions and implicit interactions between non-sequence context and user behavior.
4.3 Sequence Arch: Context-Aware Sequence Modeling¶
Behavior sequences capture dynamic interests, but they are noisy and cannot be modeled effectively in isolation. InterFormer therefore injects non-sequential context into sequence modeling.
The key component is Personalized FeedForward Network (PFFN), which transforms sequence embeddings using weights learned from non-sequence summarization. Given non-sequence summary \(\mathbf{X}_{\mathrm{sum}}^{(l)}\) and sequence embedding \(\mathbf{S}^{(l)}\):
where \(f(\cdot)\) is an MLP that learns a sequence projection conditioned on non-sequence context.
To capture token-to-token dependencies, the Sequence Arch applies MHA after PFFN. Before the first InterFormer layer, the non-sequence summary \(\mathbf{X}_{\mathrm{sum}}^{(1)}\) is prepended to the sequence as a CLS token:
This lets MHA use non-sequence information as a query for sequence aggregation. Rotary position embeddings [su2024roformer] are also applied. Overall, the Sequence Arch is:
Because the output has the same shape as the input, the architecture avoids aggressive early aggregation and supports deep stacking.
4.4 Cross Arch: Effective Information Selection and Summarization¶
Even though the Interaction and Sequence Arches preserve detailed representations, directly exchanging all features would be both noisy and expensive. The Cross Arch summarizes both sides before exchange.
For non-sequence embeddings, the model applies an MLP followed by self-gating:
Here the MLP maps from \(\mathbb{R}^{d \times n}\) to \(\mathbb{R}^{d \times n_{\mathrm{sum}}}\), where \(n_{\mathrm{sum}} \ll n\). The gating step suppresses irrelevant information and keeps only the most useful context for sequence modeling.
For sequential information, the Cross Arch combines three summaries:
- CLS tokens \(\mathbf{S}_{\mathrm{CLS}}\), which are learned by MHA and already incorporate non-sequence context.
- PMA tokens \(\mathbf{S}_{\mathrm{PMA}}\), which summarize the sequence through learnable queries.
- The \(K\) most recent interacted tokens \(\mathbf{S}_{\mathrm{recent}}\), which capture short-term interest [borisyuk2024lirank; xia2023transact].
The final sequence summary is:
The Cross Arch therefore serves two purposes: it avoids aggressive aggregation inside the main arches, and it enables efficient, low-dimensional information exchange across data modes.
5. Experiments¶
The experiments cover both public benchmark datasets and a large internal industrial dataset. The paper evaluates overall effectiveness, scaling behavior, and system-level efficiency.
5.1 Experiment Setup¶
5.1.1 Datasets¶
The paper evaluates on AmazonElectronics [he2016ups], TaobaoAds [Tianchi], KuaiVideo [li2019routing], and a large internal dataset. The three public benchmark datasets are summarized below.
| Dataset | #Samples | #Feat. (Seq/Non-Seq) | Seq Length |
|---|---|---|---|
| Amazon | 3.0M | 6 (2/4) | 100 |
| TaobaoAd | 25.0M | 22 (3/19) | 50 |
| KuaiVideo | 13.7M | 9 (⅘) | 100 |
5.1.2 Baseline Methods¶
InterFormer is compared against strong non-sequential methods and sequential methods.
Non-sequential baselines:
- FM [rendle2010factorization]
- xDeepFM [lian2018xdeepfm]
- AutoInt+ [song2019autoint]
- DCNv2 [wang2021dcn]
- FmFM [sun2021fm2]
- DOT product
- DHEN [zhang2022dhen]
- Wukong [zhang2024wukong]
Sequential baselines:
- DIN [zhou2018deep]
- DIEN [zhou2019deep]
- BST [chen2019behavior]
- DMIN [xiao2020deep]
- DMR [lyu2020deep]
- TransAct [xia2023transact]
The reported experiments instantiate InterFormer's Interaction Arch with DHEN.
5.1.3 Metrics¶
- AUC measures the model's global ranking quality. Higher is better.
- gAUC measures personalized AUC, weighting users by click count. Higher is better.
- LogLoss is cross-entropy loss: \(L(y, \hat{y}) = -\left(y\log(\hat{y}) + (1-y)\log(1-\hat{y})\right)\). Lower is better.
- NE, or Normalized Entropy [he2014practical], is LogLoss normalized by the entropy of the average training CTR. Lower is better.
5.2 Evaluation on Benchmark Datasets¶
5.2.1 Main Results¶
Sequential methods consistently outperform non-sequential methods on all datasets, which supports the paper's argument that sequential signals should not be compressed too early. InterFormer then improves further over the best sequential competitors, reaching state-of-the-art performance across all three benchmarks.
AmazonElectronics¶
| Method | gAUC | AUC | LogLoss | #Params |
|---|---|---|---|---|
| FM | 0.8494 | 0.8485 | 0.5060 | 4.23M |
| xDeepFM | 0.8763 | 0.8791 | 0.4394 | 5.46M |
| AutoInt+ | 0.8786 | 0.8804 | 0.4441 | 5.87M |
| DCNv2 | 0.8783 | 0.8807 | 0.4447 | 5.23M |
| FmFM | 0.8521 | 0.8537 | 0.4796 | 4.21M |
| DOT | 0.8697 | 0.8703 | 0.4485 | 4.23M |
| DHEN | 0.8759 | 0.8790 | 0.4398 | 4.99M |
| Wukong | 0.8747 | 0.8765 | 0.4455 | 4.28M |
| DIN | 0.8817 | 0.8848 | 0.4324 | 5.40M |
| DIEN | 0.8825 | 0.8856 | 0.4276 | 5.37M |
| BST | 0.8823 | 0.8847 | 0.4305 | 5.30M |
| DMIN | 0.8831 | 0.8852 | 0.4298 | 5.94M |
| DMR | 0.8827 | 0.8848 | 0.4309 | 6.47M |
| TransAct | 0.8835 | 0.8851 | 0.4285 | 7.56M |
| InterFormer | 0.8843 | 0.8865 | 0.4253 | 7.18M |
TaobaoAds¶
| Method | gAUC | AUC | LogLoss | #Params |
|---|---|---|---|---|
| FM | 0.5628 | 0.6231 | 0.1973 | 43.08M |
| xDeepFM | 0.5675 | 0.6378 | 0.1960 | 53.79M |
| AutoInt+ | 0.5701 | 0.6467 | 0.1941 | 42.05M |
| DCNv2 | 0.5704 | 0.6472 | 0.1933 | 43.71M |
| FmFM | 0.5698 | 0.6330 | 0.1963 | 43.06M |
| DOT | 0.5701 | 0.6482 | 0.1941 | 41.54M |
| DHEN | 0.5708 | 0.6509 | 0.1929 | 43.89M |
| Wukong | 0.5693 | 0.6478 | 0.1932 | 41.72M |
| DIN | 0.5719 | 0.6507 | 0.1931 | 42.26M |
| DIEN | 0.5721 | 0.6519 | 0.1929 | 42.38M |
| BST | 0.5698 | 0.6489 | 0.1935 | 42.05M |
| DMIN | 0.5723 | 0.6498 | 0.1933 | 42.17M |
| DMR | 0.5711 | 0.6504 | 0.1932 | 45.82M |
| TransAct | 0.5715 | 0.6498 | 0.1933 | 44.39M |
| InterFormer | 0.5728 | 0.6528 | 0.1926 | 44.73M |
KuaiVideo¶
| Method | gAUC | AUC | LogLoss | #Params |
|---|---|---|---|---|
| FM | 0.6567 | 0.7389 | 0.4445 | 52.76M |
| xDeepFM | 0.6621 | 0.7423 | 0.4382 | 43.56M |
| AutoInt+ | 0.6619 | 0.7420 | 0.4369 | 43.95M |
| DCNv2 | 0.6627 | 0.7426 | 0.4378 | 42.48M |
| FmFM | 0.6552 | 0.7389 | 0.4429 | 51.97M |
| DOT | 0.6605 | 0.7435 | 0.4361 | 41.29M |
| DHEN | 0.6589 | 0.7424 | 0.4365 | 42.06M |
| Wukong | 0.6587 | 0.7423 | 0.4372 | 41.37M |
| DIN | 0.6621 | 0.7437 | 0.4353 | 43.03M |
| DIEN | 0.6651 | 0.7451 | 0.4343 | 43.43M |
| BST | 0.6617 | 0.7446 | 0.4352 | 42.83M |
| DMIN | 0.6623 | 0.7449 | 0.4356 | 41.61M |
| DMR | 0.6642 | 0.7449 | 0.4355 | 44.15M |
| TransAct | 0.6632 | 0.7448 | 0.4352 | 42.97M |
| InterFormer | 0.6637 | 0.7453 | 0.4340 | 43.61M |
InterFormer improves over the best competitor by up to 0.9% in gAUC, 0.14% in AUC, and 0.54% in LogLoss according to the paper's summary.
5.2.2 Analysis of the Model¶
Interleaving Learning Style¶
The paper studies five scenarios for three different non-sequence backbones: DOT, DCNv2, and DHEN.
- sole: only the Interaction Arch is used, and sequence information is aggregated early.
- sep: the Interaction and Sequence Arches are both used, but inter-mode information exchange is disabled.
- s2n: only sequence-to-non-sequence information flow is enabled.
- n2s: only non-sequence-to-sequence information flow is enabled.
- int: full bidirectional information flow is enabled.
The results support a consistent ranking: sole < sep < n2s ~= s2n < int.
This pattern suggests that bidirectional information exchange is more effective than either one-way interaction or no interaction.
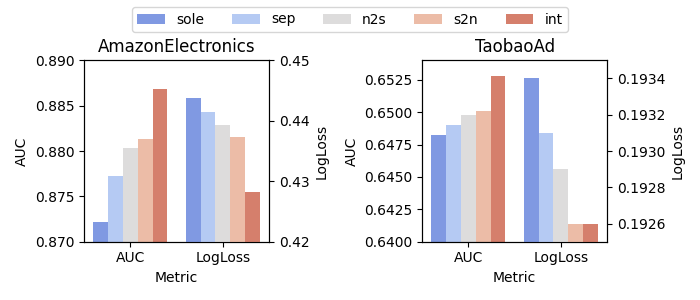
Figure 2a. Interleaving learning study with DOT as the Interaction Arch backbone.
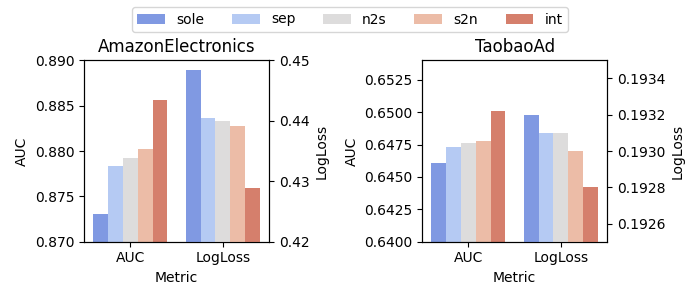
Figure 2b. Interleaving learning study with DCNv2 as the Interaction Arch backbone.
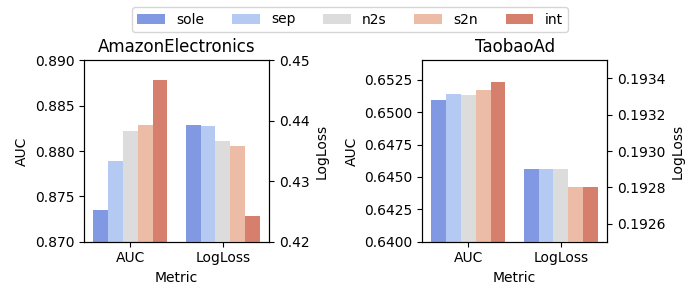
Figure 2c. Interleaving learning study with DHEN as the Interaction Arch backbone.
Selective Information Aggregation¶
The paper compares InterFormer's selective aggregation with three aggressive early-compression variants: average pooling, MLP compression, and MHA compression. InterFormer performs best across the comparison, which supports the idea that more selective and later aggregation preserves more useful information.
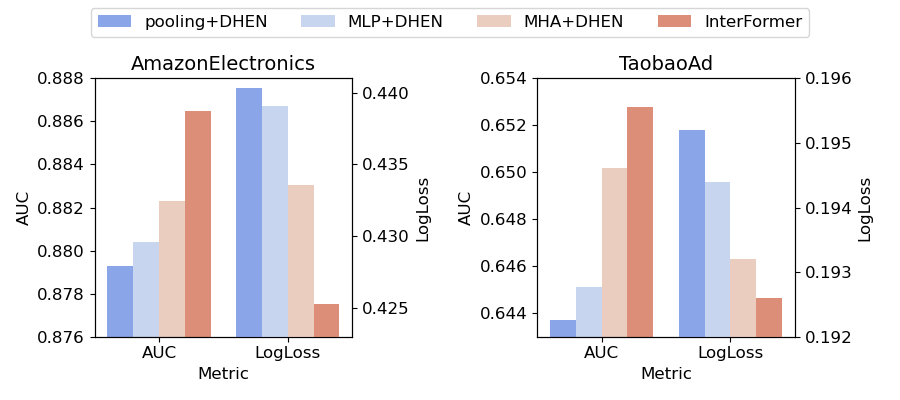
Figure 3. InterFormer's selective aggregation compared with average pooling, MLP-based compression, and MHA-based compression.
Sequence Modeling Behavior¶
The learned attention maps show clear cluster structure. Nearby tokens often interact strongly, suggesting a selective pooling mechanism over local neighborhoods. Different layers also attend at different scales. Early layers show broad, relatively uniform attention that may correspond to long-term interest aggregation, while deeper layers focus on smaller, more specific clusters, which may correspond to short-term or item-specific interest.
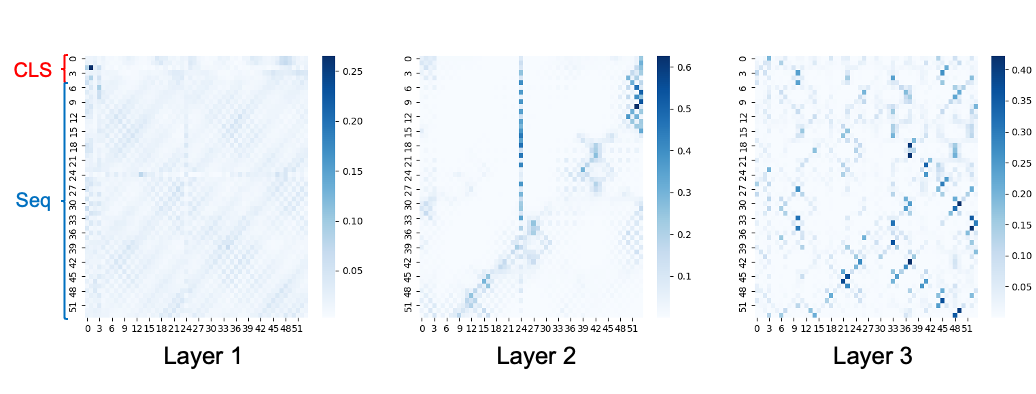
Figure 4. Attention map on TaobaoAds. The first four tokens are CLS tokens, followed by a behavior sequence of length 50.
Ablation Study¶
The ablation removes different exchanged summaries and internal modules, including PMA tokens, recent interacted tokens, gating modules, PFFN, and MHA. Every component contributes to the final result. PMA tokens appear especially important, and the paper reports that removing them can reduce AUC by up to 0.004.
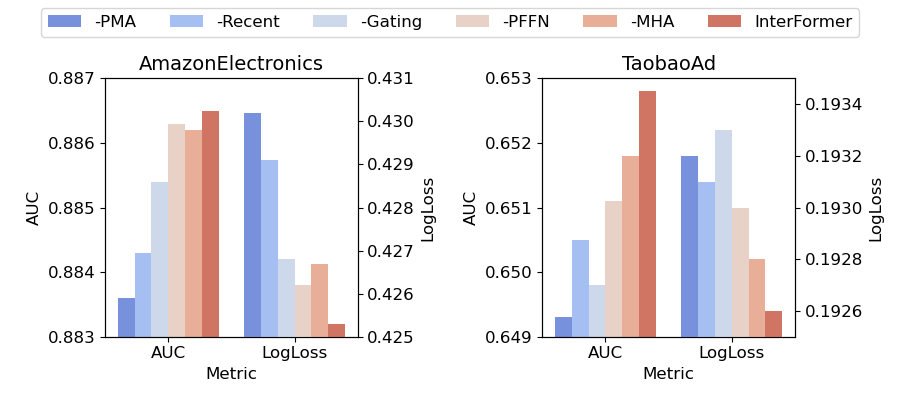
Figure 5. Ablation study on InterFormer. A minus sign indicates that the corresponding information source or module is removed.
5.3 Evaluation on Industrial Datasets¶
The industrial evaluation uses a large internal Meta dataset with 70B samples, hundreds of non-sequence features, and 10 sequences of length 200 to 1,000.
5.3.1 Results¶
According to the paper, a 3-layer InterFormer achieves a 0.15% NE gain over the internal state-of-the-art model under similar FLOPs, together with a 24% QPS gain. Combined with feature scaling, the gain grows further while maintaining about 10% MFU on 512 GPUs.
Sequence Feature Scaling¶
The paper studies what happens when the amount of sequence information increases. In addition to six sequences of length 100, it adds two long sequences of length 1,000 and observes a further 0.14% NE improvement. InterFormer shows a stronger scaling curve than the internal baseline, and the gap reaches 0.06% in NE. The authors also experiment with merging six sequences into a single sequence of length 600, which improves QPS by 20% and MFU by 17% at the cost of a 0.02% NE drop.
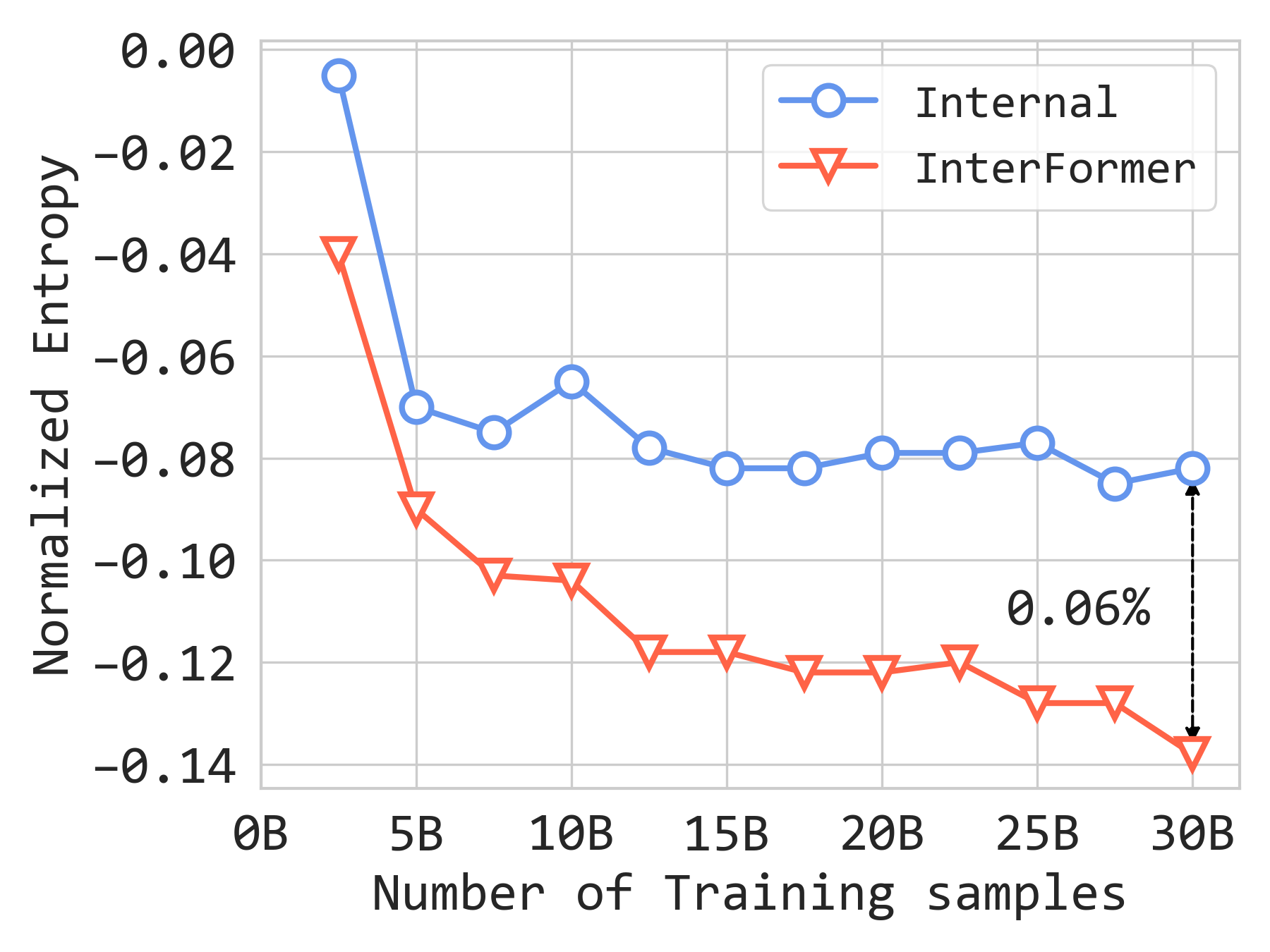
Figure 6a. Feature scaling results on the internal dataset.
Model Scaling¶
InterFormer also scales well with depth. Moving from one layer to two layers yields a 0.13% NE gain, and adding a third and fourth layer yields additional gains of 0.05% and 0.04% respectively.
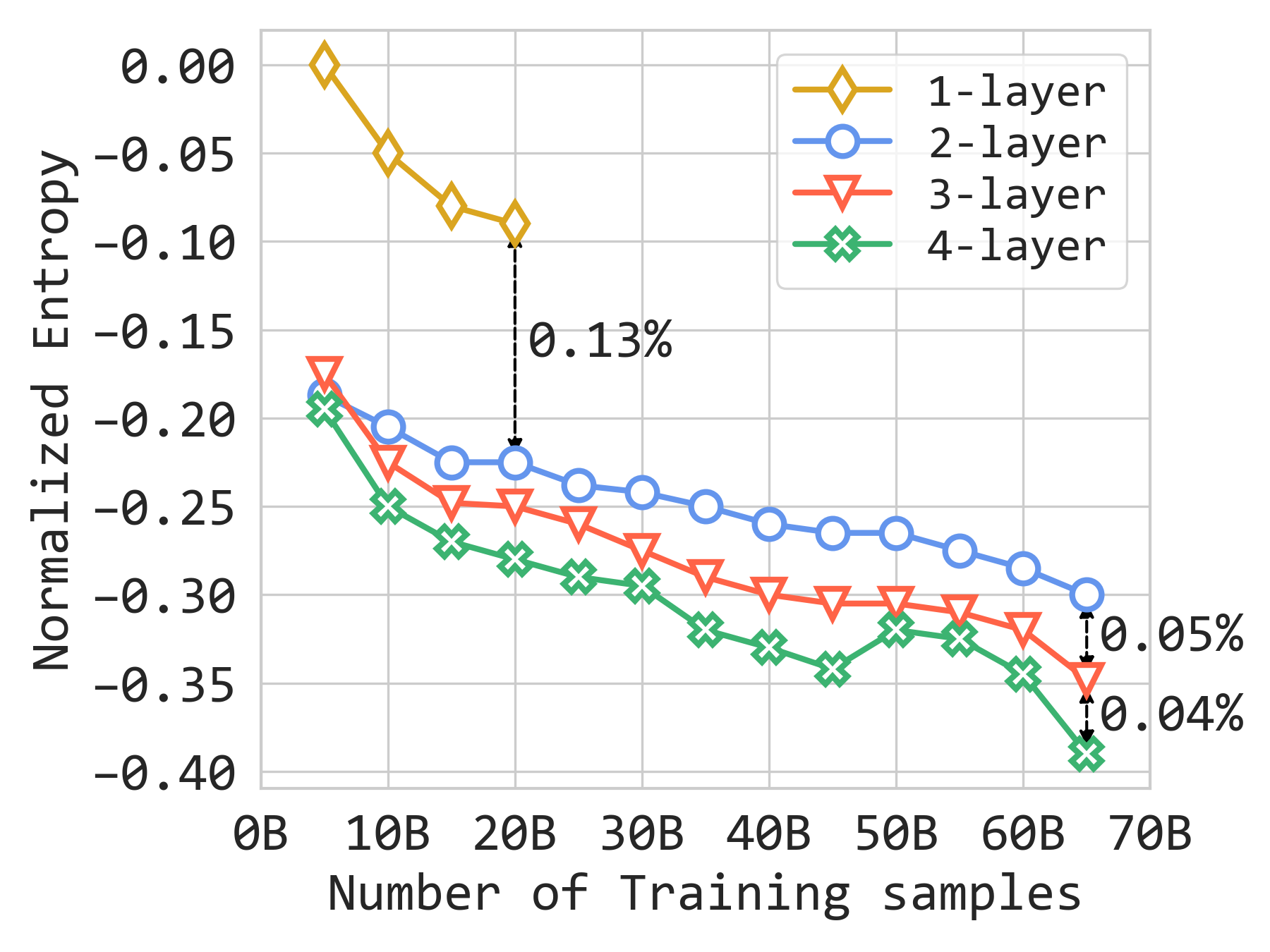
Figure 6b. Model scaling results on the internal dataset.
Overall, the two scaling plots show that InterFormer benefits both from more sequence information and from deeper stacking.
5.3.2 Model-System Co-Design¶
The paper highlights two optimizations that improve overall training efficiency by more than 30%:
- Communication overhead reduction. The DHEN-based Interaction Arch is communication-bound under FSDP [zhao2023pytorch], while the Transformer-based Sequence Arch is more computation-bound. Since the two arches run in parallel, exposed communication from the Interaction Arch can overlap with sequence computation, yielding about 20% QPS improvement over a sequential execution schedule.
- Computation efficiency. The system reallocates FLOPs from low-return modules to higher-return modules and fuses smaller kernels for better GPU utilization. The paper reports that these changes improve MFU for interaction modules from 11% to 16%, DHEN from 38% to 45%, and the overall InterFormer layer by 19%.
5.3.3 Online Impact¶
InterFormer has been deployed in important Meta Ads models, including very large ones referenced by the paper, and pilot launches in 2024 reportedly produced a 0.6% improvement in topline metrics.
6. Conclusion¶
InterFormer is presented as a heterogeneous interaction block for CTR prediction that combines an Interaction Arch, a Sequence Arch, and a Cross Arch. Its main design principle is interleaving learning between different data modes, so sequential and non-sequential representations can refine each other instead of interacting only once and only in one direction. The model also separates representation learning from summarization, which helps avoid aggressive information aggregation. Across benchmarks and large-scale industrial deployment, the paper reports consistent gains in quality, scaling behavior, and serving efficiency.
Appendix¶
A. Model Design¶
A.1 Algorithm¶
The original appendix presents the following high-level procedure for InterFormer:
- Input non-sequence feature \(\mathbf{X}^{(0)}\), sequence feature \(\mathbf{S}^{(0)}\), and number of layers \(L\).
- Preprocess non-sequence and sequence features to obtain \(\mathbf{X}^{(1)}\) and \(\mathbf{S}^{(1)}\).
- Compute the initial non-sequence summary \(\mathbf{X}_{\mathrm{sum}}^{(1)}\).
- Prepend \(\mathbf{X}_{\mathrm{sum}}^{(1)}\) to the sequence as CLS tokens.
- For each layer \(l = 1, 2, \dots, L\):
- Use the Cross Arch to compute \(\mathbf{X}_{\mathrm{sum}}^{(l)}\) and \(\mathbf{S}_{\mathrm{sum}}^{(l)}\).
- Use the Interaction Arch to compute \(\mathbf{X}^{(l+1)}\) from \(\mathbf{X}^{(l)}\) and \(\mathbf{S}_{\mathrm{sum}}^{(l)}\).
- Use the Sequence Arch to compute \(\mathbf{S}^{(l+1)}\) from \(\mathbf{S}^{(l)}\) and \(\mathbf{X}_{\mathrm{sum}}^{(l)}\).
- Produce the final CTR prediction:
- Return \(\hat{y}\).
A.2 More Details on Module Blocks¶
Linear Compressed Embedding¶
Given \(N\) features \(\mathbf{X} \in \mathbb{R}^{d \times N}\), Linear Compressed Embedding (LCE) applies a linear transformation \(\mathbf{W} \in \mathbb{R}^{N \times M}\) so that:
acts as a compressed embedding with \(M\) features. Combined with self-gating, LCE both compresses and denoises large feature collections.
Personalized FFN¶
PFFN models interaction between non-sequence and sequence features by learning an FFN weight from summarized non-sequence context. Given \(\mathbf{X}_{\mathrm{sum}} \in \mathbb{R}^{d \times n_{\mathrm{sum}}}\) and \(\mathbf{S} \in \mathbb{R}^{d \times T}\), it first learns:
and then applies that transformation to the sequence representation:
Unlike a standard Transformer FFN, this version explicitly injects information from another data mode.
B. Experiment Pipeline¶
The benchmark experiments use the public BARS evaluation framework [zhu2022bars]. Optimization uses Adam [kingma2014adam] with a learning-rate scheduler. The initial learning rate is tuned over \(\{10^{-1}, 10^{-2}, 10^{-3}\}\). Training uses a batch size of 2048 and runs for up to 100 epochs with early stopping. Swish [ramachandran2017searching] is used as the activation function. NVIDIA A100 GPUs are used for benchmark experiments and NVIDIA H100 GPUs are used for internal experiments.
B.1 Datasets¶
- AmazonElectronics [he2016ups]. Contains product reviews and metadata from Amazon with 192,403 users, 63,001 goods, 801 categories, and 1,689,188 samples. Non-sequence features include user ID, item ID, and item category. Sequence features include interacted items and their categories with length 100. The split used in the paper contains 2.60M training samples and 0.38M test samples.
- TaobaoAds [Tianchi]. Contains 8 days of Taobao ad click-through data, about 26 million records from 1,140,000 users. Non-sequence features include item-related features such as ad ID, category, and price, plus user-related features such as user ID, gender, and age. Sequence features include interacted-item brands, interacted-item categories, and user behaviors with length 50. The paper uses 22.0M training samples and 3.1M test samples.
- KuaiVideo [li2019routing]. Contains 10,000 users and 3,239,534 interacted micro-videos. Non-sequence features include user ID, video ID, and visual video embeddings. Sequence features include multiple behaviors such as click, like, and not-click, with length 100. The split used in the paper contains 10.9M training samples and 2.7M test samples.
- Internal. Contains 70B entries, hundreds of non-sequence features, and 10 sequences of length 200 to 1,000.
B.2 Model Configuration¶
The paper states that it uses the best BARS-searched configurations when possible, while other baselines use their default hyperparameters. In general:
- Attention MLP sizes are chosen from {512, 256, 128, 64}.
- The number of attention heads is chosen from {1, 2, 4, 8}.
- The classifier head uses an MLP with sizes {1024, 512, 256, 128}.
Model-specific notes:
- xDeepFM: the compressed interaction network uses an MLP of size 32.
- DCNv2: the parallel structure uses an MLP of size 512, the stacked structure uses an MLP of size 500, and the low-rank parameter of the cross layer is set to 32.
- DHEN: the ensemble uses DOT product and DCN modules, and the number of layers is searched over {1, 2, 3}.
- InterFormer: the number of CLS tokens is 4, the number of PMA tokens is 2, and the number of recent tokens is 2.